1.Handler消息机制
Handler 被设计出来的原因?有什么用?
Handler 的意义就是切换线程
作为 Android 消息机制的主要成员,它管理着所有与界面有关的消息事件,常见的使用场景有:
- 跨进程之后的界面消息处理。 Binder 线程到主线程
比如 Activity 的启动,就是 AMS 在进行进程间通信的时候,通过 Binder 线程将消息发送给 ApplicationThread 的消息处理者 Handler,然后再将消息分发给主线程中去执行。 - 网络交互后切换到主线程进行 UI 更新
总之一句话,Hanlder 的存在就是为了解决在子线程中无法访问 UI 的问题。
Android 在主线程是不能加载网络数据或图片、数据库查询、复杂业务逻辑处理以及费时任务操作,因为 Android 的 UI 操作并不是线程安全的,并且所有涉及 UI 的操作必须在 UI 线程中完成。Android 应用在5s 内无响应的话会导致 ANR (Application Not Response)
Java 指定某个线程执行?不行。必须写循环
Android 的 Handler 机制
本质:在某个指定的运行中的线程上执行代码
思路:在接受任务的线程上执行循环判断
Looper:负责循环、条件判断和任务执行
Handler:负责任务的定制和线程间传递
Executor、AsyncTask、HandlerThead、IntentService 的选择
原则:哪个简单用哪个
- 能用 Executor 就用 Executor
- 需要用到「后台线程推送任务到 UI 线程」时,再考虑 AsyncTask 或者 Handler
- HandlerThread 的使用场景:原本它设计的使用场景是「在已经运行的指定线程上执行代码」,但现实开发中,除了主线程之外,几乎没有这种需求,因为 HandlerThread 和 Executor 相比在实际应用中并没什么优势,反而用起来会麻烦一点。不过,这二者喜欢用谁就用谁吧。

Handler 流程
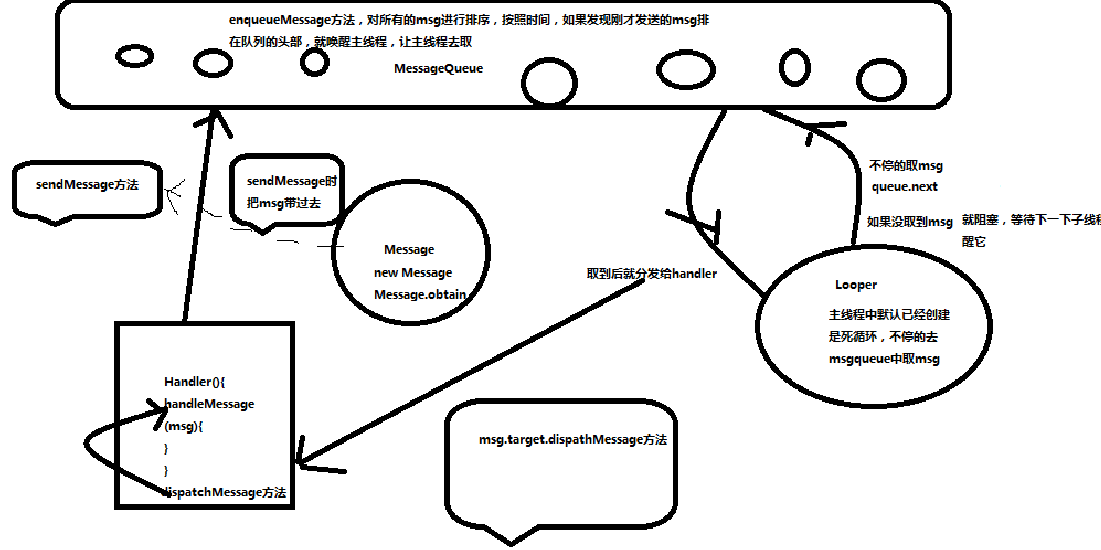
- 一般会在子线程中创建 message 对象,通过 handler 的 sendmessage 方法把消息发送到 messageQueue 队列(单链表)里,队列是先进先出的
- 在队列里通过 enqueueMessage 方法对所有的 message 按时间为顺序从小到大排列 (通过 msg. next),如果发现刚才发送的 message 排在队列的最前头,就唤醒主线程,让主线程去取 (looper)
- 在主线程的 activityThraead 类默认已经创建 looper 对象,在 new looper 的时候构造方法里创建了 messagequeue 对象。
- looper 调用 loop 方法(一直是主线程里),里面又不停的调用 mQueue 的 next 方法,从 messagequeue 里取消息(for (;;) ),这是个阻塞式方法(死循环)
- 取到消息后通过 msg. tagre(也就是 Handler). dispatchMessage 方法分发消息,里面又调用了 handlermessage 方法将消息交给 handler 处理,刷新 ui
如何从子线程切换到主线程的?
线程间是共享资源的
- handler 将自己的引用间接被 Looper 持有,handler 的构造函数里有 looper,是主线程的 looper。就算没有,也会创建一个 mLooper:当前线程中的 Looper 对象。
- 构造的时候就是主线程的 handler
- 所以 handler. sendMessage (),这里 handler 在主线程。
- 当 Looper 在主线程调用 loop ()方法时,该方法会取出 handler 并调用其 handleMessage ()方法,这样就切换到了主线程。
- handler 的创建的时候采用的是当前线程的 Looper 来构造消息系统,Looper 在哪个线程创建, 就在哪个线程绑定, 并且 handler 是在他关联的消息系统来处理的。
为什么建议子线程不访问(更新)UI
因为 Android 中的 UI 控件不是线程安全的,如果多线程访问 UI 控件那还不乱套了。那为什么不加锁呢?
- 会降低 UI 访问的效率。本身 UI 控件就是离用户比较近的一个组件,加锁之后自然会发生阻塞,那么 UI 访问的效率会降低,最终反应到用户端就是这个手机有点卡。
- 太复杂了。本身 UI 访问时一个比较简单的操作逻辑,直接创建 UI,修改 UI 即可。如果加锁之后就让这个 UI 访问的逻辑变得很复杂,没必要。
所以,Android 设计出了单线程模型来处理 UI 操作,再搭配上 Handler,是一个比较合适的解决方案。
子线程访问 UI 的崩溃原因和解决办法
崩溃发生在 ViewRootImpl 类的 checkThread 方法中:
1 | |
其实就是判断了当前线程是否是 ViewRootImpl 创建时候的线程,如果不是,就会崩溃。
而 ViewRootImpl 创建的时机就是界面被绘制的时候,也就是 onResume 之后,所以如果在子线程进行 UI 更新,就会发现当前线程(子线程)和 View 创建的线程(主线程)不是同一个线程,就会抛异常。
解决办法有三种:
- 在新建视图的线程进行这个视图的 UI 更新,主线程创建 View,主线程更新 View。
- 子线程切换到主线程进行 UI 更新,比如 Handler、view. post 方法。
- Android 中有⼀个控件 SurfaceView ,它可以通过 holder 获得 canvas 对象,可以直接在⼦线程中更新 UI。
只有创建了 view 树的线程,才能访问它的子 view。并没有说子线程一定不能访问 UI。那可以猜想到,button 的确实是在子线程被添加到 window 中的,子线程确实可以直接访问。
- 在⼦线程中创建 ViewRootImpl,自己创建,最好不要这么做
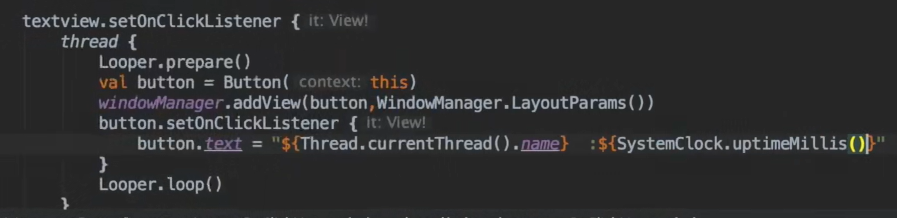
子线程可以 showToast, 只要在前后调 Looper. prepare ()和 Looper. loop ()即可。show 的过程就是添加 Window 的过程。
只有调用了 Looper. prepare ()方法,才会构造一个 Looper 对象并在 ThreadLocal 存储当前线程的 Looper 对象。
1
2
3
4
5
6
7
8
9
10new Thread(new Runnable() {
@Override
public void run() {
Looper.prepare();//Looper初始化
//Handler初始化 需要注意, Handler初始化传入Looper对象是子线程中缓存的Looper对象
mHandler = new Handler(Looper.myLooper());
Looper.loop();//死循环
//注意: Looper.loop()之后的位置代码在Looper退出之前不会执行,(并非永远不执行)
}
}).start();
MessageQueue
用的什么数据结构来存储数据?
看名字应该是个队列结构,队列的特点是什么?先进先出,一般在队尾增加数据,在队首进行取数据或者删除数据。
那 Hanlder 中的消息似乎也满足这样的特点,先发的消息肯定就会先被处理。但是,Handler 中还有比较特殊的情况,比如延时消息。
延时消息的存在就让这个队列有些特殊性了,并不能完全保证先进先出,而是需要根据时间来判断,所以 Android 中采用了链表的形式来实现这个队列,也方便了数据的插入。
创建是 native,核心内容就是初始化一个 NativeMessageQueue 对象,并将其地址返回给 Java 层。
来一起看看消息的发送过程,无论是哪种方法发送消息,都会走到 sendMessageDelayed 方法
1 | |
sendMessageDelayed 方法主要计算了消息需要被处理的时间,如果 delayMillis 为0,那么消息的处理时间就是当前时间。
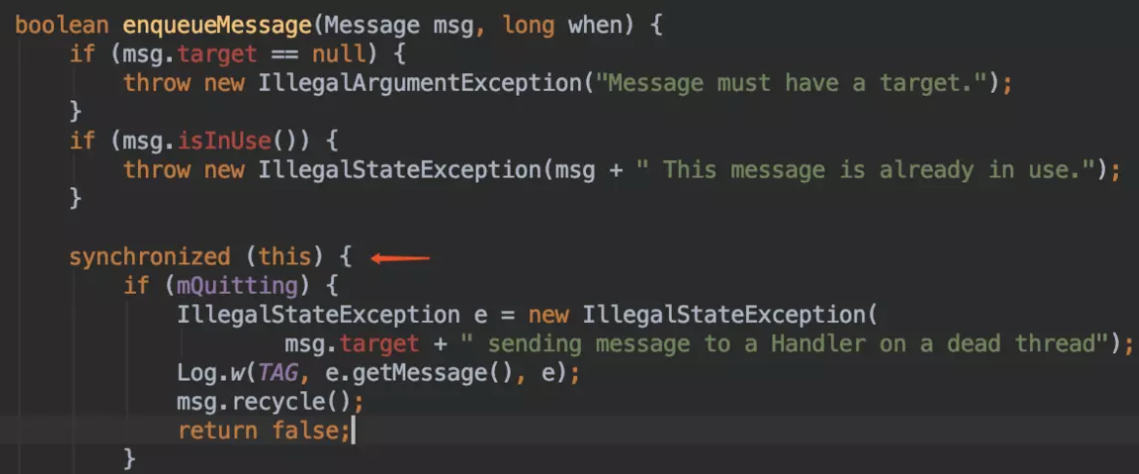
然后就是关键方法 MessageQueue 的方法 enqueueMessage。
1 | |
不懂得地方先不看,只看我们想看的:
- 首先设置了 Message 的 when 字段,也就是代表了这个消息的处理时间
- 然后判断当前队列是不是为空,是不是即时消息,是不是执行时间 when 大于表头的消息时间,满足任意一个,就把当前消息 msg 插入到表头。
1 | |
- 否则,就需要遍历这个队列,也就是链表,找出 when 小于某个节点的 when,找到后插入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16else {
needWake = mBlocked && p.target == null && msg.isAsynchronous();
Message prev;
for (; ; ) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
if (needWake && p.isAsynchronous()) {
needWake = false;
}
}
msg.next = p;
prev.next = msg;
}
插入消息就是通过消息的执行时间,也就是 when 字段(当前时间+延迟时间),来找到合适的位置插入链表。
具体方法就是通过死循环,使用快慢指针 p 和 prev,每次向后移动一格,直到找到某个节点 p 的 when 大于我们要插入消息(msg)的 when 字段,则插入到 p 和 prev 之间。或者遍历到链表结束,插入到链表结尾。
所以,MessageQueue 就是一个用于存储消息、用链表实现的特殊队列结构。
延迟消息是怎么实现的
无论是即时消息还是延迟消息,都是计算出具体的时间,然后作为消息的 when 字段进程赋值。
然后在 MessageQueue 中找到合适的位置(安排 when 小到大排列),并将消息插入到 MessageQueue 中。
这样,MessageQueue 就是一个按照消息时间排列的一个链表结构。
MessageQueue 的消息怎么被取出来的
刚才说过了消息的存储,接下来看看消息的取出,Looper.loop ——loopOnce
1 | |
queue. next 方法。
1 | |
为什么取消息也是用的死循环呢?
其实死循环就是为了保证一定要返回一条消息,如果没有可用消息,那么就阻塞在这里,一直到有新消息的到来。
其中,nativePollOnce 方法就是阻塞方法,nextPollTimeoutMillis 参数就是阻塞的时间。那什么时候会阻塞呢?两种情况:
- 1、有消息,但是当前时间小于消息执行时间,也就是代码中的这一句:
1 | |
这时候阻塞时间=消息时间减去当前时间,然后进入下一次循环,阻塞。
- 2、没有消息的时候,也就是上述代码的最后一句:
1 | |
-1就代表一直阻塞。
阻塞之后怎么唤醒
说说 pipe/epoll 机制
接着上文的逻辑,当消息不可用或者没有消息的时候就会阻塞在 next 方法,而阻塞的办法是通过 pipe/epoll 机制
epoll 原理
[[Linux相关#IO 多路复用]]
epoll 机制是一种 IO 多路复用的机制,具体逻辑就是一个进程可以监视多个描述符,当某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作,这个读写操作是阻塞的。在 Android 中,会创建一个 Linux 管道(Pipe)来处理阻塞和唤醒。
- 当消息队列为空,管道的读端等待管道中有新内容可读,就会通过 epoll 机制进入阻塞状态。
- 当有消息要处理,就会通过管道的写端写入内容,唤醒主线程。
那什么时候会怎么唤醒消息队列线程呢?
还记得刚才插入消息的 enqueueMessage 方法中有个 needWake 字段吗,很明显,这个就是表示是否唤醒的字段。
其中还有个字段是 mBlocked,看字面意思是阻塞的意思,去代码里面找找:
1 | |
在获取消息的方法 next 中,有两个地方对 mBlocked 赋值:
- 当获取到消息的时候,mBlocked 赋值为 false,表示不阻塞。
- 当没有消息要处理,也没有 idleHandler 要处理的时候,mBlocked 赋值为 true,表示阻塞。
好了,确实这个字段就表示是否阻塞的意思,再去看看 enqueueMessage 方法中,唤醒机制:
1 | |
当链表为空或者时间小于表头消息时间,那么就插入表头,并且设置是否唤醒为 mBlocked。
再结合上述的例子,也就是当有新消息要插入表头了,这时候如果之前是阻塞状态(mBlocked=true),那么就要唤醒线程了。否则,就需要取链表中找到某个节点并插入消息,在这之前需要赋值 needWake = mBlocked && p.target == null && msg. isAsynchronous ()(是否是异步消息)
也就是在插入消息之前,需要判断是否阻塞,并且表头是不是屏障消息( p.target == null),并且当前消息是不是异步消息。也就是如果现在是同步屏障模式下,那么要插入的消息又刚好是异步消息,那就不用管插入消息问题了,直接唤醒线程,因为异步消息需要先执行。
- 最后一点,是在循环里,如果发现之前就存在异步消息,那就还是设置是否唤醒为 false。意思就是,如果之前有异步消息了,那肯定之前就唤醒过了,这时候就不需要再次唤醒了。
最后根据 needWake 的值,决定是否调用 nativeWake 方法唤醒 next()方法。
Handler 里的各种消息
[[2.Handler 里的各种消息]]
Message 消息分发之后的处理
消息怎么复用的?
再看看 loop 方法,在消息被分发之后,也就是执行了 dispatchMessage 方法之后,还偷偷做了一个操作——recycleUnchecked。
1 | |
在 recycleUnchecked 方法中,释放了所有资源,然后将当前的空消息插入到 sPool 表头。
这里的 sPool 就是一个消息对象池,它也是一个链表结构的消息,最大长度为50。
享元模式 Message. obtain
在使用 handler 的时候发现,创建 message 对象有两种方式,一种是直接 new,一种是使用 Message. obtain (),这个 message 的静态方法是这样实现的:
1 | |
解释:
首先,它会检查 sPool 是否为 null。如果 sPool 不为 null,说明之前已经创建过 Message 对象并放入了对象池中。然后直接复用消息池 sPool 中的第一条消息,然后 sPool 指向下一个节点,消息池数量减一。
Looper
Looper是干嘛呢?怎么获取当前线程的 Looper?为什么不直接用 Map 存储线程和对象呢?
在 Handler 发送消息之后,消息就被存储到 MessageQueue 中,而 Looper 就是一个管理消息队列的角色。 Looper 会从 MessageQueue 中不断的查找消息,也就是 loop 方法,并将消息交回给 Handler 进行处理。而 Looper 的获取就是通过 ThreadLocal 机制:
[[5.ThreadLocal]]
1 | |
通过 prepare 方法创建 Looper 并且加入到 sThreadLocal 中,通过 myLooper 方法从 sThreadLocal 中获取 Looper。
Looper 中的 quitAllowed 字段
按照字面意思就是是否允许退出,那么这个 quit 方法一般是什么时候使用呢?
- 主线程中,一般情况下肯定不能退出,因为退出后主线程就停止了。所以是当 APP 需要退出的时候,就会调用 quit 方法
- 子线程中,如果消息都处理完了,就需要调用 quit 方法停止消息循环。
死循环
Looper. loop 方法是死循环,为什么不会卡死(ANR)
- 1、主线程本身就是需要一只运行的,因为要处理各个 View,界面变化。所以需要这个死循环来保证主线程一直执行下去,不会被退出。可执行代码是能一直执行下去的,死循环便能保证主线程不会被退出
- 2、真正会卡死的操作是在某个消息处理的时候操作时间过长,导致掉帧、ANR,而不是 loop 方法本身。
- 3、在主线程以外,会有其他的线程来处理接受其他进程的事件,比如 Binder 线程(ApplicationThread),会接受 AMS 发送来的事件,比如屏幕刷新16ms 一个消息,你的各种点击事件,都会唤醒
- 4、在收到跨进程消息后,会交给主线程的 Hanlder 再进行消息分发。所以 Activity 的生命周期都是依靠主线程的 Looper. loop,当收到不同 Message 时则采用相应措施,比如收到 msg=H.LAUNCH_ACTIVITY,则调用 ActivityThread.handleLaunchActivity ()方法,最终执行到 onCreate 方法。
- 5、当没有消息的时候,会阻塞在 loop 的 queue.next ()中的 nativePollOnce ()方法里,此时主线程会释放 CPU 资源进入休眠状态,直到下个消息到达或者有事务发生。所以死循环也不会特别消耗 CPU 资源。
对于线程来说,既然是一段可执行的代码,当可执行的代码执行完后,线程的生命周期就该终止了,线程也就退出。而对于主线程,我们是绝不希望运行一段时间自己就退出的。
那么如何保证能一直存活呢?简单的做法就是让可执行的代码一直执行下去,死循环就可以保证不被退出。例如:loop () 方法中就是采用 for (;;) 死循环的方式。
Message 分发消息
在 loop 方法中,找到要处理的 Message,然后调用了这么一句代码处理消息:
1 | |
所以是将消息交给了 msg. target 来处理,那么这个 target 是啥呢?
找找它的来头:
1 | |
在使用 Hanlder 发送消息的时候,会设置 msg. target = this,所以 target 就是当初把消息加到消息队列的那个 Handler。
post (Runnable) 与 sendMessage
Hanlder 中主要的发送消息可以分为两种:
- post (Runnable)
- sendMessage
post 这个方法是把任务 r 转成一个 message 放进了 handler 所在的线程中的 messageQueue 消息队列中,并且是立刻发送的消息,这样它既不是异步的也不是延时的
handler. post 和 handler. sendMessage 本质上是没有区别的,都是发送一个消息到消息队列中,只是实际用法中有一点差别, post 也没有独特的作用,post 本质上还是用 sendMessage 实现的,post 只是一中更方便的用法而已
通过 post 的源码可知,其实 post 和 sendMessage 的区别就在于:post 方法给 Message 设置了一个 callback。
那么这个 callback 有什么用呢?我们再转到消息处理的方法 dispatchMessage 中看看:
1 | |
这段代码可以分为三部分看:
- 1、如果 msg. callback 不为空,也就是通过 post 方法发送消息的时候,会把消息交给这个 msg. callback 进行处理,然后就没有后续了。
- 2、如果 msg. callback 为空,也就是通过 sendMessage 发送消息的时候,会判断 Handler 当前的 mCallback 是否为空,如果不为空就交给 Handler. Callback. handleMessage 处理。
- 3、如果 mCallback. handleMessage 返回 true,则无后续了。
- 4、如果 mCallback. handleMessage 返回 false,则调用 handler 类重写的 handleMessage 方法。
所以 post (Runnable) 与 sendMessage 的区别就在于后续消息的处理方式,是交给 msg. callback 还是 Handler. Callback 或者 Handler. handleMessage。
postdelay
- 把消息放到过几秒再放到消息队列里,遍历循环链表找到最后一个时间比当前要插入的消息的时间小的消息。
- postDelay 本质还是交给 MessageQueue 去处理的, 然后在 next 方法里面, 调用 nativePollOnce 进行阻塞, nativePollOnce 类似 Object 的 wait 方法, 只不过用了 native 方法对线程精确时间的唤醒。
Handler. Callback. handleMessage 和 Handler. handleMessage
有什么不一样?为什么这么设计
接着上面的代码说,这两个处理方法的区别在于 Handler. Callback. handleMessage 方法是否返回 true:
- 如果为 true,则不再执行 Handler. handleMessage
- 如果为 false,则两个方法都要执行。
那么什么时候有 Callback,什么时候没有呢?这涉及到两种 Hanlder 的创建方式:
1 | |
常用的方法就是第1种,派生一个 Handler 的子类并重写 handleMessage 方法。而第2种就是系统给我们提供了一种不需要派生子类的使用方法,只需要传入一个 Callback 即可。
Handler、Looper、MessageQueue、线程
- 一个线程只会有一个 Looper 对象,所以线程和 Looper 是一一对应的。
- MessageQueue 对象是在 new Looper 的时候创建的,所以 Looper 和 MessageQueue 是一一对应的。
- Handler 的作用只是将消息加到 MessageQueue 中,并后续取出消息后,根据消息的 target 字段分发给当初的那个 handler,所以 Handler 对于 Looper 是可以多对一的,也就是多个 Hanlder 对象都可以用同一个线程、同一个 Looper、同一个 MessageQueue。
总结:Looper、MessageQueue、线程是一一对应关系,而他们与 Handler 是可以一对多的。
IdleHandler
[[4.IdleHandler]]
HandlerThread
为了让我们在子线程里面更方便的使用 Handler
HandlerThread 其实就是一个单线程,和 new singinthreadExecutor 效果一样。
HandlerThread 自己做了 prepare 和 loop
IntentService 就是用的 HandlerThread
用法:
- 先创建一个 HandlerThread,然后 start
- 创建 handler,构造函数是 HandlerThread 的 looper
- handler sendMessage
- handleMessage 里运行在子线程里了,做完操作可以用主线程 handler 发送消息给主线程
- 用完 HandlerThread. quit ();
1 | |
HandlerThread 类的简化版源码,用于理解其基本原理和实现方式:
1 | |
HandlerThread 使用场景
- 执行多个耗时任务,并且这些任务需要按顺序执行(串行执行),简单的单线程池
- 需要将任务从主线程切换到后台线程执行,避免阻塞UI线程。
其他用法
1 | |
IntentService
1 | |
理一下这个源码:
- 首先,这是一个 Service
- 并且内部维护了一个 HandlerThread,也就是有完整的 Looper 在运行。
- 还维护了一个子线程的 ServiceHandler。
- 启动 Service 后,会通过 Handler 执行 onHandleIntent 方法。
- 完成任务后,会自动执行 stopSelf 停止当前 Service。
所以,这就是一个可以在子线程进行耗时任务,并且在任务执行后自动停止的 Service。
利用 Handler 机制设计一个不崩溃的 App
主线程崩溃,其实都是发生在消息的处理内,包括生命周期、界面绘制。
所以如果我们能控制这个过程,并且在发生崩溃后重新开启消息循环,那么主线程就能继续运行。
1 | |
还有一些特殊情况处理,比如 onCreate 内发生崩溃,具体可以看看文章
《能否让 APP 永不崩溃》 juejin.cn/post/690428…
post 一个 Runnable ,在下一帧就可以拿到了?
- 这个说不准,如果上一条 Message 在 callback 中 sleep 了5秒,那就在5秒之后才会取出了。。。
- 说到屏幕刷新(也就是这个“下一帧”),在 View 中倒是有个方法可以让 Runnable 在下一次屏幕刷新时执行,它就是:postOnAnimation (Runnable action)!
- 相信很多同学在看 View 类源码的时候都会看到过它的身影,比如 RecyclerView 在处理惯性滚动时就会反复调用这个方法(在每一次屏幕刷新时才计算滚动后的坐标值,而不是开子线程去不停计算,以节省资源)
runOnUiThread
1 | |
new Handler ()与 new Handler (Looper. getMainLooper ())
要刷新 UI,handler 要用到主线程的 Looper 对象。那么在主线程 Handler handler=new Handler () 如果在其他非主线程也要满足这个功能的话,要 Handler handler=new Handler (Looper.getMainLooper ());
如何确保线程安全的
既然可以存在多个 Handler 往 MessageQueue 中添加数据(发消息时各个 Handler 可能处于不同线程),那它内部是如何确保线程安全的?
这里主要关注 MessageQueue 的消息存取即可,看源码内部的话,在往消息队列里面存储消息时,会拿当前的 MessageQueue 对象作为锁对象,这样通过加锁就可以确保操作的原子性和可见性了。
消息的读取也是同理,也会拿当前的 MessageQueue 对象作为锁对象,来保证多线程读写的一个安全性。
自定义简单 Handler
1 | |