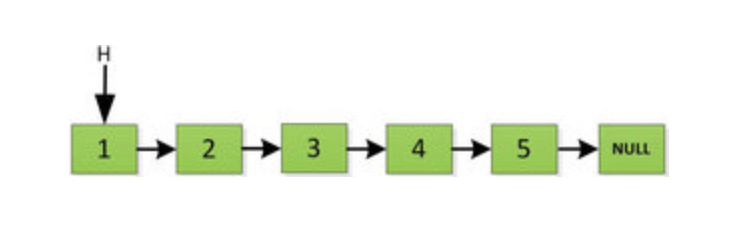
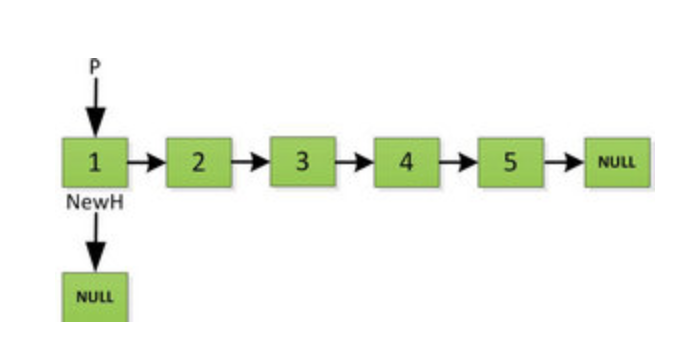
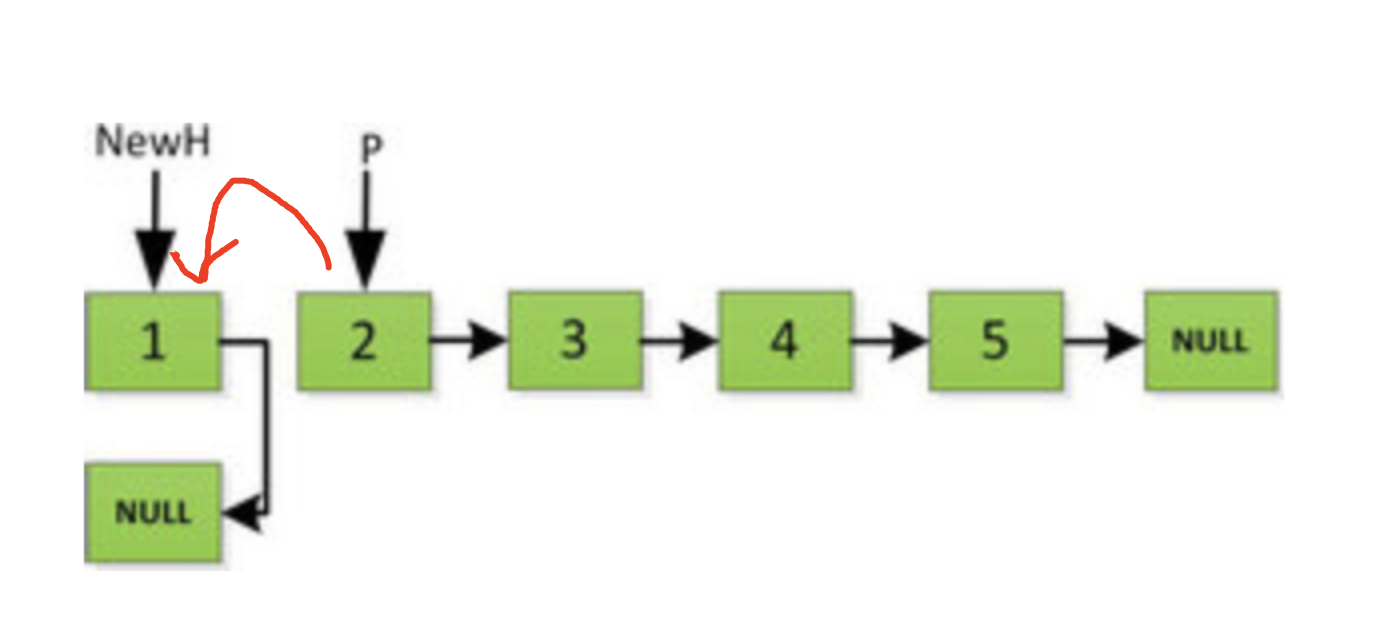
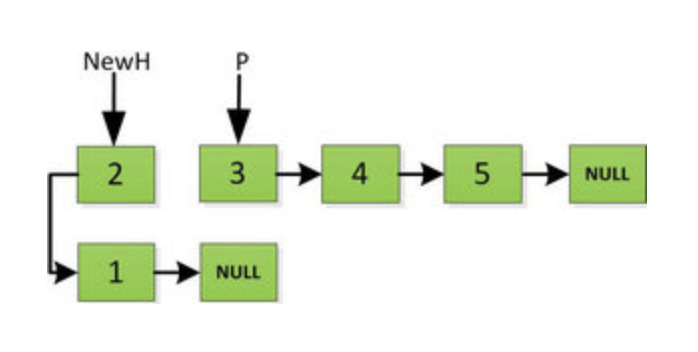
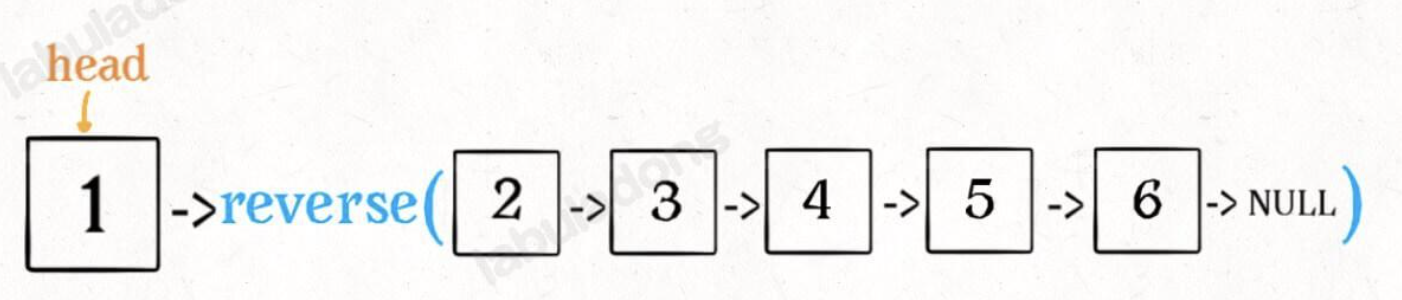
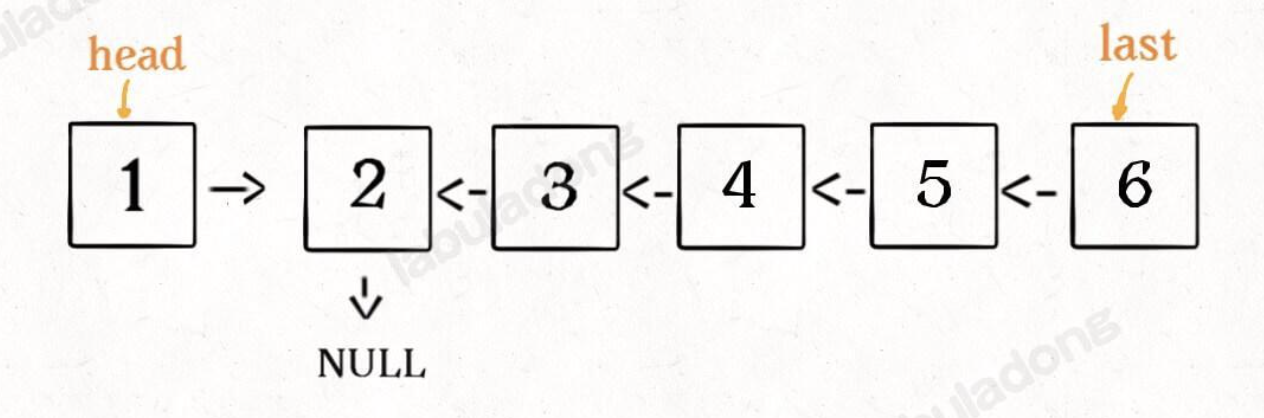
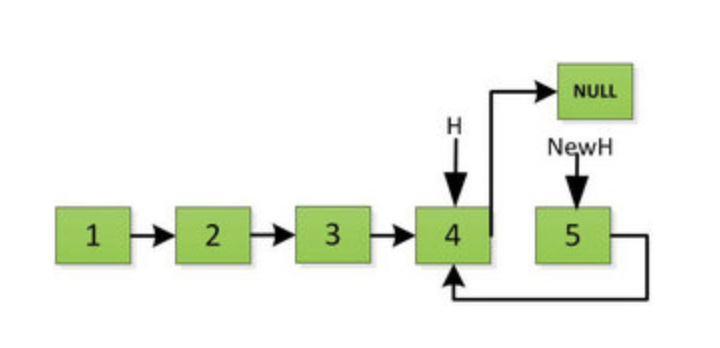
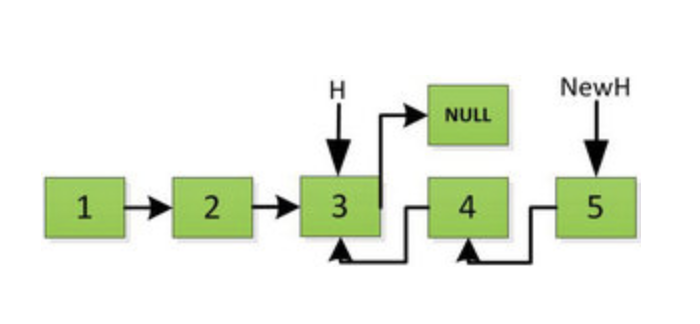
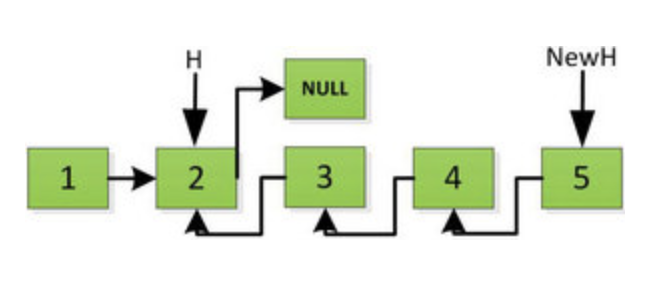
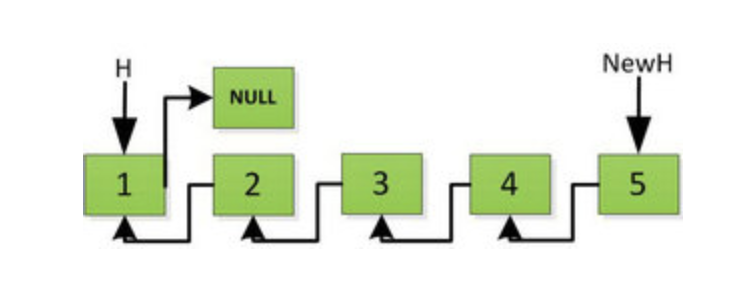
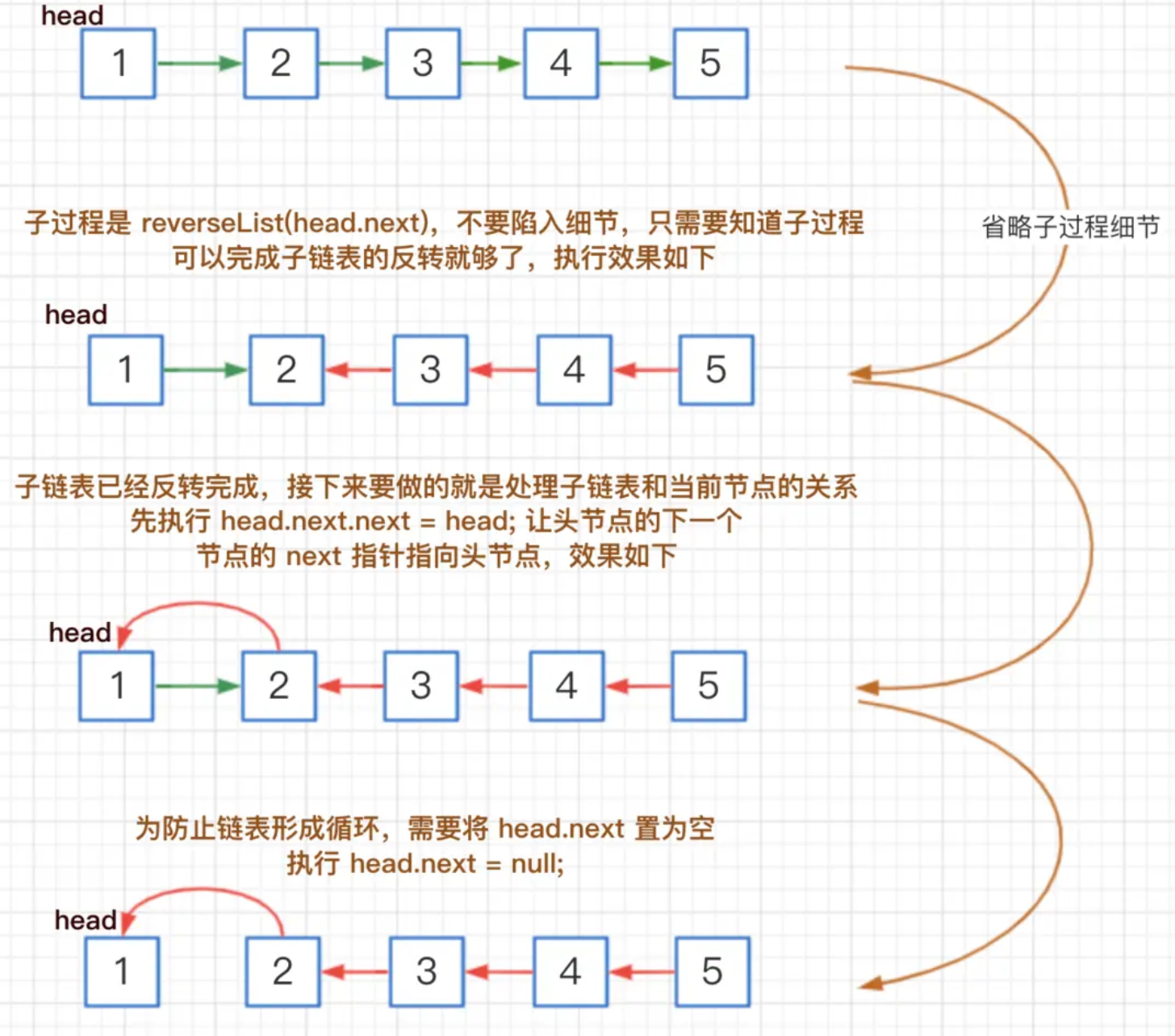
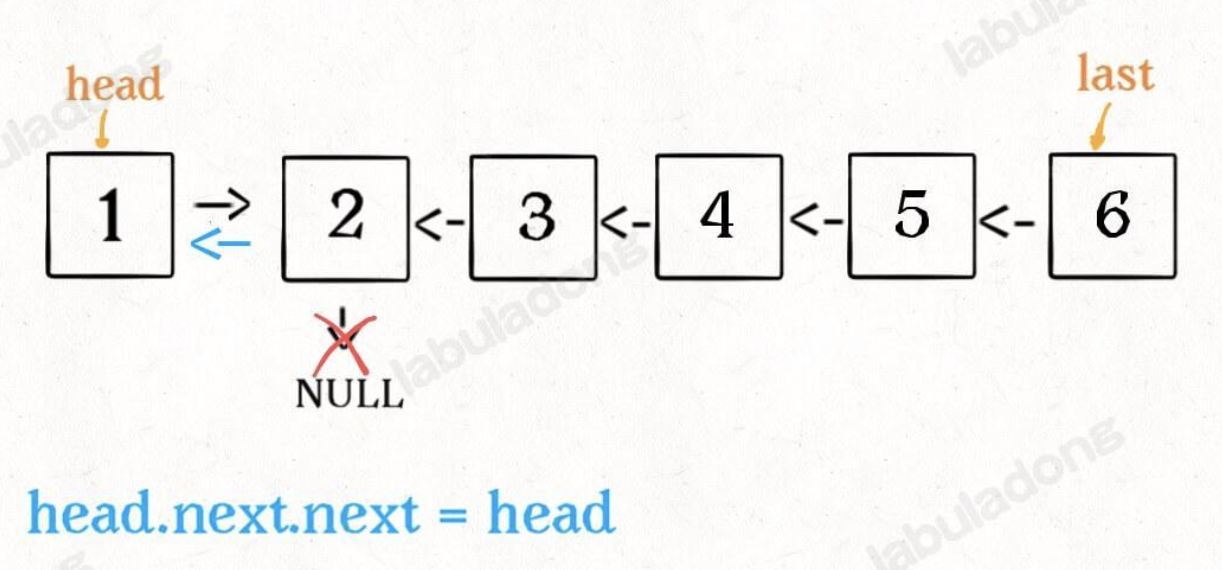然后 H 指针逐层返回的时候依次做下图的处理,将 H 指向的地址赋值给 H->next->next 指针,*4的 next 5的 next 指向4,4指向 null *
继续返回操作:
上图第一次如果没有将存放4空间的 next 指针赋值指向 NULL,第二次 H->next->next=H,就会将存放5的地址空间覆盖为3,这样链表一切都大乱了。接着逐层返回下去,直到对存放1的地址空间处理。
第三种解释
二、反转链表前 N 个节点
1 2
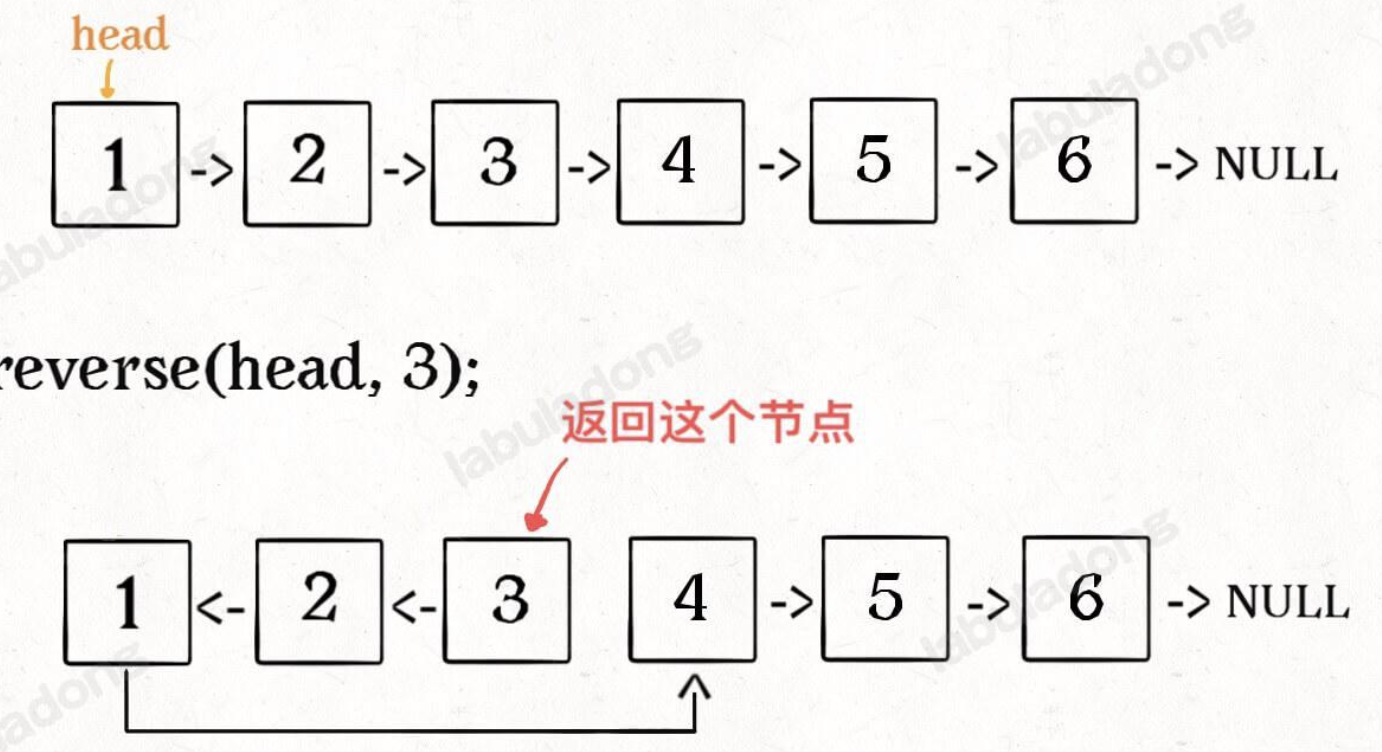
// 将链表的前 n 个节点反转(n <= 链表长度) ListNode reverseN(ListNode head, intn)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
ListNode successor = null; // 后驱节点
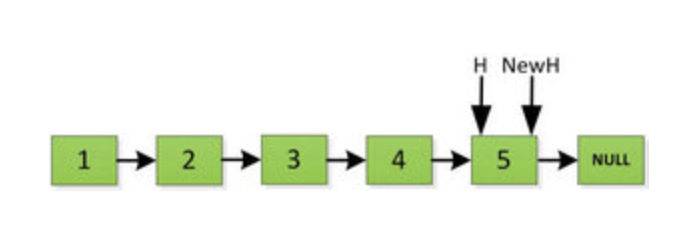
// 反转以 head 为起点的 n 个节点,返回新的头结点 ListNode reverseN(ListNode head, int n) { if (n == 1) { // 记录第 n + 1 个节点 successor = head.next; return head; } // 以 head.next 为起点,需要反转前 n - 1 个节点 ListNode last = reverseN(head.next, n - 1);
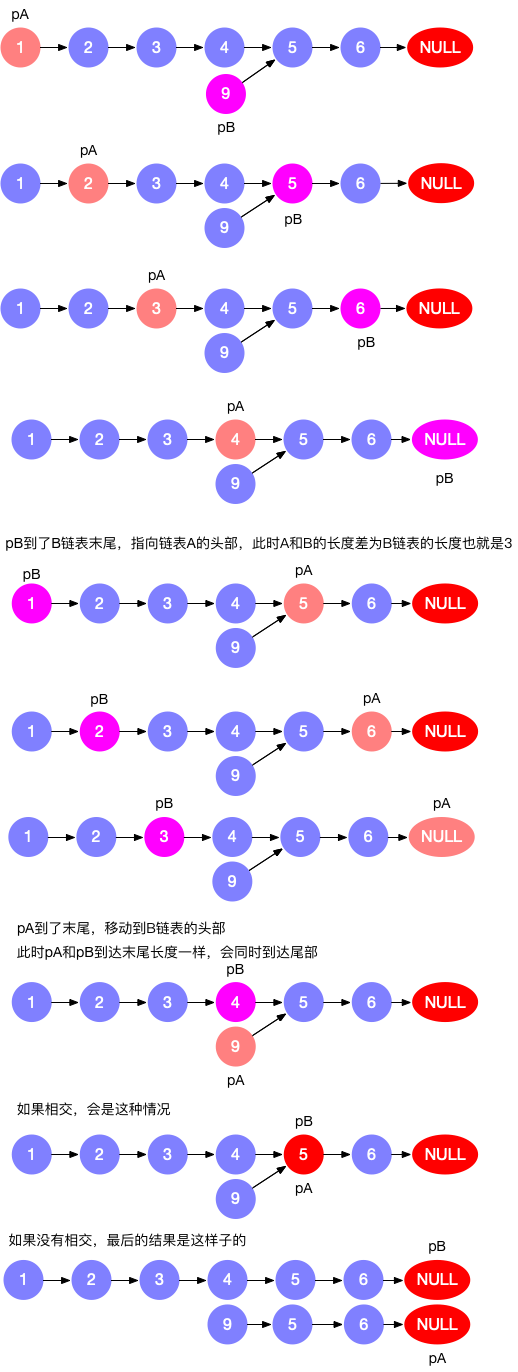
指针 pA 指向 A 链表,指针 pB 指向 B 链表,依次往后遍历 如果 pA 到了末尾,则 pA = headB 继续遍历 如果 pB 到了末尾,则 pB = headA 继续遍历 比较长的链表指针指向较短链表 head 时,长度差就消除了 如此,只需要将最短链表遍历两次即可找到位置 听着可能有点绕,看图最直观,链表的题目最适合看图了
1 2 3 4 5 6 7 8 9
public ListNode getIntersectionNode(ListNode headA, ListNode headB) { if (headA == null || headB == null) returnnull; ListNodepA= headA, pB = headB; while (pA != pB) { pA = pA == null ? headB : pA.next; pB = pB == null ? headA : pB.next; } return pA; }
其他理解
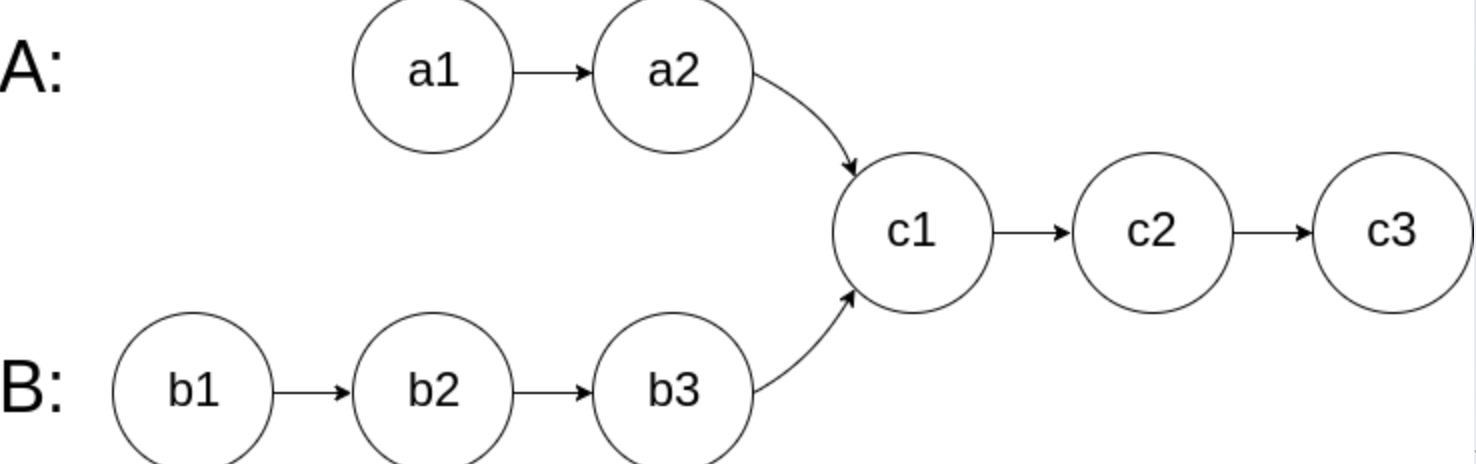
pA 走过的路径为 A 链+B 链 pB走过的路径为B链+A链 pA 和 pB 走过的长度都相同,都是 A 链和 B 链的长度之和,相当于将两条链从尾端对齐,如果相交,则会提前在相交点相遇,如果没有相交点,则会在最后相遇。
两个人速度一致,走过的路程一致。那么肯定会同一个时间点到达终点
其实就是让2个指针走一样的距离,消除步行差,那就一定可以一起走到相交点
若相交,链表 A: a+c, 链表 B : b+c. a+c+b+c = b+c+a+c 。则会在公共处 c 起点相遇。若不相交,a +b = b+a 。因此相遇处是 NULL