2.ANR及问题排查
ANR
什么是 ANR
ANR 全称 Applicatipon No Response;Android 设计 ANR 的用意,是系统通过与之交互的组件 (Activity,Service,Receiver,Provider) 以及用户交互 (InputEvent) 进行超时监控,以判断应用进程 (主线程) 是否存在卡死或响应过慢的问题。其实就是很多系统中看门狗 (watchdog) 的设计思想。
Android 在主线程是不能做阻塞耗时操作的,例如加载网络数据、数据库查询、文件读写,如果在应用中无响应的话会导致 ANR (Application Not Response)
手机可分配的 CPU 占满也会发生 ANR
没有在规定的时间内,干完要干的事情,就会发生 ANR。也有可能不是自己应用的问题
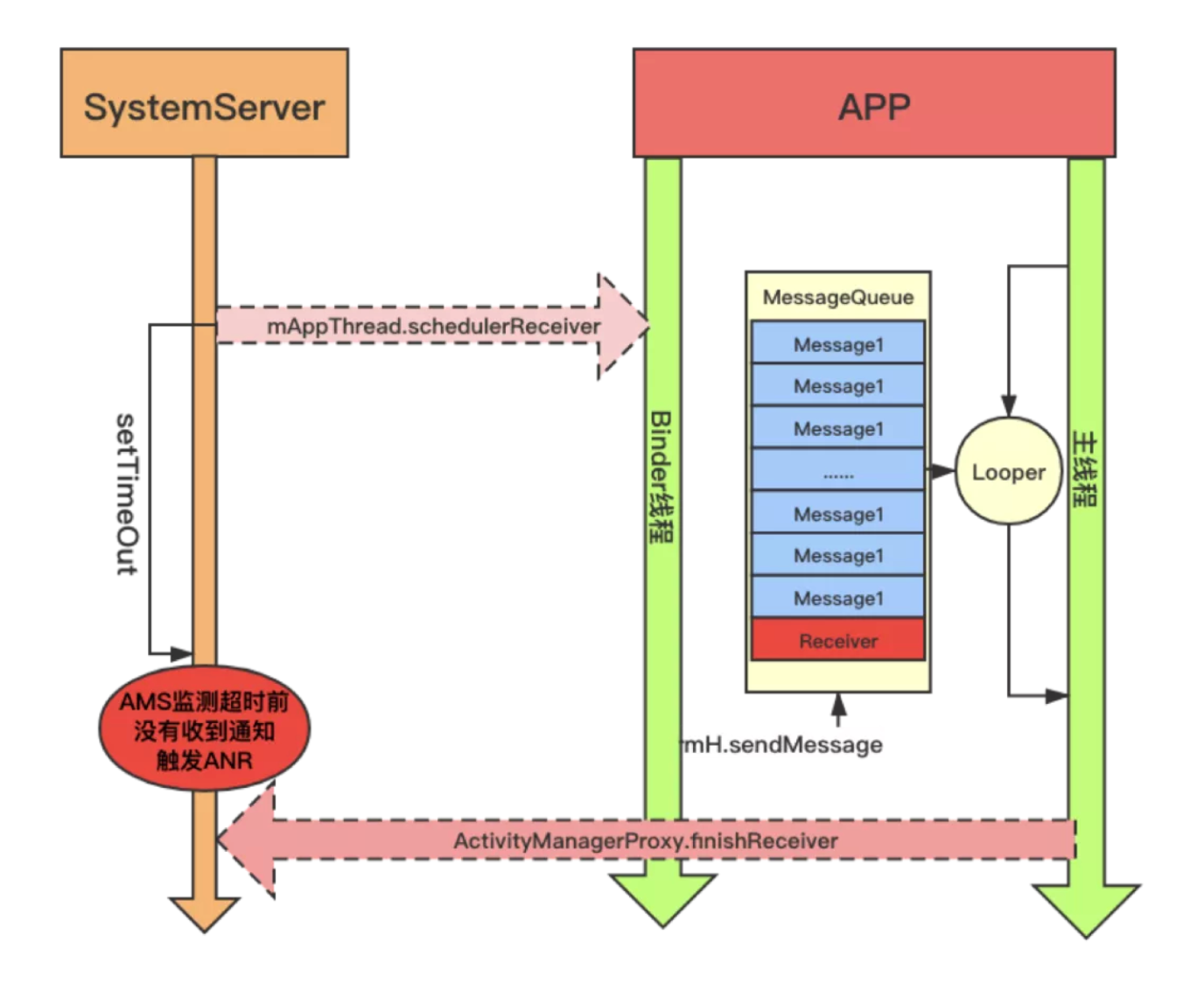
ANR 触发流程解析
SystemServer(系统服务进程)
- 通过
setTimeOut设置广播接收的超时阈值(前台广播 10 秒,后台广播 60 秒) - 通过 Binder 线程向 APP 发送广播:
mAppThread.scheduleReceiver()
- 通过
APP 进程接收广播
- Binder 线程收到广播后,向主线程的
MessageQueue插入消息(图中多个Message1) - 消息内容:要求执行
Receiver.onReceive()
- Binder 线程收到广播后,向主线程的
主线程处理延迟
- 主线程正处理其他消息(
Message1队列积压) - 无法及时执行广播接收器的
onReceive()方法
- 主线程正处理其他消息(
AMS 监控超时
- ActivityManagerService (AMS) 在后台计时
- 超时前未收到
ActivityManagerProxy.finishReceiver()完成通知
触发 ANR
- AMS 检测超时后,判定应用无响应
- 系统弹出 ANR 对话框并记录日志
分类
根据具体的原因和场景,可以将 ANR 分为以下几种类型:
Input dispatching timeout
- 主线程卡住没处理输入事件(touch/key)
- 典型:UI线程执行耗时操作
BroadcastQueue timeout
- 广播接收器
onReceive()超时
- 广播接收器
Service timeout
onCreate()或onStartCommand()耗时
ContentProvider timeout
- 主线程在
ContentProvider的onCreate()、query()阻塞
- 主线程在
system_server Watchdog
- 关键系统服务(AMS/WMS/PMS)卡住
5s 内没有响应用户输入事件
10s 内广播接收器没有处理完毕
20s 内服务没有处理完毕
造成 ANR 的常见原因
- 应用在主线程上进行长时间的计算、耗时的 I/O 的操作。
- 主线程处于阻塞状态,等待获取锁。
- 主线程与其他线程之间发生死锁。
- 主线程在对另一个进程进行同步 Binder 调用,而后者需要很长时间才能返回。(如果我们知道调用远程方法需要很长时间,我们应该避免在主线程调用)
A.主线程耗时操作,如复杂的layout,庞大的for循环,IO等。
B.主线程被子线程同步锁block
C.主线程被Binder 对端block
D.Binder被占满导致主线程无法和SystemServer通信
E.得不到系统资源(CPU/RAM/IO)
分析 anr
adb pull /data/anr/traces. txt trace. txt
ANR 产生时, 系统会生成一个 traces. txt 的文件放在/data/anr/下. 可以通过 adb 命令将其导出到本地,这个文件里有 ANR 发生的进程 pid, 时间, 以及进程名字 (包名),还有 anr 产生的位置和方法。最新的 ANR 信息在最开始部分。
[[Trace 文件怎么读]]
主要原因是主线程做了耗时操作(io、网络、数据库)
- 先 确定发生 ANR 的时间具体时间点、什么类型的 anr
- 当 ANR 被发现后,两个很重要的日志输出是:CPU 使用情况和进程的函数调用栈,这两类日志是我们解决 ANR 问题的关键
- 看 cpu,如果 cpu 占用很高,说明主线程可能阻塞。
- 看线程转态,是阻塞还是等待
- 看 stackSize
第一步: 确定发生ANR的时间具体时间点、什么类型的 anr
- event log,通过检索”am_anr”关键字,可以找到发生 ANR 的应用
- main log,通过检索”ANR in “关键字,可以找到 ANR 的信息,日志的上下文会包含 CPU 的使用情况
- 往下翻找到“main”线程则可看到对应的阻塞 log
根据这行log我们确定的信息
发生anr的时间点:12-17 06:02:14.463,
进程pid:8769,
进程名:com.android.updater,
发生ANR的类型是:BroadcastTimeout,
发生的具体类或者原因:{ act=android.intent.action.BOOT_COMPLETED flg=0x9000010 cmp=com.android.updater/.BootCompletedReceiver (has extras) }
eg:
1 | |
这行日志中很多信息是和Events log是重合的,但是我们我们可以通过” started 60006ms ago“可以知道这信息是在1分多钟之前执行的,现在还没有执行结束,已经达到了发生ANR规定的时间,可以确定这是个后台广播,所以我们可以把信息锁定在时间点:12-17 06:02:00.370往前推算的一分钟内,观察在这段时间内具体执行了哪些操作,导致后台广播没有执行完成.
注意:
- ANR in对应的ANR的时间点往往是比am_anr的时间点是靠后的,一般不使用这个时间确定ANR发生的具体时间点
- cpu占用95%有时候并不算高,在多核中每个核最大占用率都是100%(八核占用率是800%)
第二步:ANR发生时打印的堆栈和系统附加信息
发生ANR时,各个应用进程和系统进程的函数堆栈信息都输出到了一个/data/anr/traces.txt的文件.我们往往比较关注的是发生ANR的应用进程主线程具体执行堆栈,我们可以知道在发生ANR这个时间点主线程具体在做什么,为什么卡住了,是等锁,binder call调用还是主线程存在耗时的操作等等.
eg:
main(线程名)、prio(线程优先级,默认是5)、tid(线程唯一标识ID)、Sleeping(线程当前状态)
“main” prio=5 tid=1 Sleeping
| group=”main” sCount=1 dsCount=0 obj=0x73132d10 self=0x5598a5f5e0
//sysTid是线程号(主线程的线程号和进程号相同)
| sysTid=17027 nice=0 cgrp=default sched=0/0 handle=0x7fb6db6fe8
| state=S schedstat=( 420582038 5862546 143 ) utm=24 stm=18 core=6 HZ=100
| stack=0x7fefba3000-0x7fefba5000 stackSize=8MB
| held mutexes=
// java 堆栈调用信息(这里可查看导致ANR的代码调用流程)(分析ANR最重要的信息)
at java.lang.Thread.sleep!(Native method)
- sleeping on <0x0c60f3c7> (a java.lang.Object)
at java.lang.Thread.sleep(Thread.java:1031) - locked <0x0c60f3c7> (a java.lang.Object) // 锁住对象0x0c60f3c7
at java.lang.Thread.sleep(Thread.java:985)
at android.os.SystemClock.sleep(SystemClock.java:120)
at org.code.ipc.MessengerService.onCreate(MessengerService.java:63) //导致ANR的代码
at android.app.ActivityThread.handleCreateService(ActivityThread.java:2877)
at android.app.ActivityThread.access$1900(ActivityThread.java:150)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1427)
at android.os.Handler.dispatchMessage(Handler.java:102)
at android.os.Looper.loop(Looper.java:148)
at android.app.ActivityThread.main(ActivityThread.java:5417)
at java.lang.reflect.Method.invoke!(Native method)
at com.android.internal.os.ZygoteInit$MethodAndArgsCaller.run(ZygoteInit.java:726)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:616)
查看系统耗时关键字: binder_sample、dvm_lock_sample、am_lifecycle_sample、binder thread
结合源码和以上的信息进行分析
具体例子
- 主线程获取播放器总时长
- 主线程上执行复杂的布局计算,例如嵌套的布局层次、动态布局调整或复杂的测量和布局过程,主线程可能会花费过长的时间来计算布局,recycleview 嵌套,csharpReason: Input dispatching timed out
- 读一个大文件
- 主线程中执行长时间的动画操作,可以启动硬件加速、或者如果动画操作涉及到后台任务,例如加载和处理大量图像数据,可以考虑使用异步任务来在后台线程上执行这些操作,并在完成后在主线程上更新动画。
- 调 h5方法太频繁或耗时
- 在主线程上执行大量的图像处理操作,例如图片压缩、滤镜处理或大型图像的加载和显示,大图优化。内存紧张导致 ANR
解决办法
- 不要在主线程 (UI 线程) 里面做繁重的操作, 增大 VM 内存, 使用 largeHeap 属性, 排查内存泄露
- Thread + Handler + Message ,Thread + Handler + post,AsyncTask,intentservice、runOnUiThread (Runnable) 在子线程中直接使用该方法,可以更新 UI,记得注意内存泄露
锁
比较少,大部分是做了耗时操作
主线程处于阻塞状态,等待获取锁
先让后台线程获取锁,做耗时操作,然后主线程再尝试获取锁。然后多次点击返回键,制造ANR。
1 | |
在等待一个锁对象 <0x0f8c80b0>,该对象是一个 Object 对象(a java.lang.Object),这个锁对象正在被线程id为16的线程持有。那么我们下面在traces.txt文件中搜索一下这个锁对象 <0x0f8c80b0>,然后找到对应代码
主线程与其他线程之间发生死锁
traces.txt部分信息
1 | |
通过进程号pid 13626搜索
1 | |
主线程状态是线程状态是Blocked,说明正在等待获取锁对象,等待获取的锁对象<0x0a43b5c8>是一个String对象(a java.lang.String),该对象被线程id为17的线程持有。然后我们搜索这个锁对象。
traces关注点
traces.txt 里的主要关注点
ANR 发生时,系统会把当时所有进程的线程堆栈 dump 到 /data/anr/traces.txt。常看这些:
main 线程堆栈(UI线程)
state(状态:Running / Sleeping / Blocked)- 是否在等待锁(
- locked、- waiting to lock) - 是否在 Binder 调用(跨进程阻塞)
- 是否有耗时操作(IO、sleep、数据库、循环计算等)
Binder 线程池(Binder_xxx)
- 否卡在某个系统服务 / 应用 Service 调用上
- 常见问题:binder 死锁 / binder 队列阻塞
GC / FinalizerDaemon / ReferenceQueueDaemon
- 是否 GC 卡顿
- 是否对象回收线程停滞,拖慢主线程
系统服务进程(system_server)
ActivityManager、InputDispatcher、WindowManager的堆栈- 重点:system_server 如果被卡住,所有 app 都可能 ANR
traces.txt 里的关键 tag(系统打的日志点)
你提到的几个关键字,其实是 systrace/atrace 打点 + ANR 打印扩展,能辅助定位卡点:
binder_sample
- 说明 Binder 调用超时,可能是调用方 / 被调用方处理过慢。
- binder thread 堆栈能看到调用的接口。
dvm_lock_sample / art_lock_sample
- 表示 Java 锁竞争严重,有线程长时间持有锁。
- 常见场景:主线程
synchronized锁住,子线程要获取;或者数据库锁未释放。
am_lifecycle_sample
- ActivityManager 监控到某个 生命周期回调耗时。
- 比如
onCreate()、onResume()、onStart()超时。
binder thread
- binder 线程池的堆栈信息,可以看到是否卡在等待 / 处理事务。
这些信息配合system_server和 app 主线程堆栈一起看,能快速定位卡因。
- binder 线程池的堆栈信息,可以看到是否卡在等待 / 处理事务。
线上问题排查
adb bugreport
生成的 log 位于 /data/user_de/0/com. android. shell/files/bugreports/ 目录下
如何查看 FC:
- 搜索关键字 system_app_crash am_crash
- 关键字 AndroidRuntime
- F DEBUG ,native 崩溃会用到
- 日志打点怕打太多也怕太少,担心出现问题没有足够丰富的信息去定位分析问题。应该打多少日志,如何去打日志并没有一个非常严格的准则,这需要整个团队在长期实践中慢慢去摸索。在最开始的时候,可能大家都不重视也不愿意去增加关键代码的日志,但是当我们通过日志平台解决了一些疑难问题以后,团队内部的成功案例越来越多的时候,这种习惯也就慢慢建立起来了。
- 使用 Mars 的 xlog,Java 实现写日志,GC 频繁,而 C 实现并不会出现这种情况,因为它不会占用 Java 的堆内存。
- 使用阿里云日志采集服务
- 俩种方式上报日志:push 上报,主动上报(在用户出现奔溃,反馈问题时主动上报日志(可以重启了上报))
- 正因为反复“痛过”,才会有了微信的用户日志和点击流平台,才会有美团的 Logan 和 Homles(看看) 统一日志系统。所谓团队的“提质增效”,就是寻找团队中这些痛点,思考如何去改进。无论是流程的自动化,还是开发新的工具、新的平台,都是朝着这个目标前进。
Android 混淆后还怎么看错误
保留关键信息:在混淆配置文件(通常是 proguard-rules.pro)中,您可以添加规则来保留某些类、方法或字段的名称,以便在混淆后的应用程序中仍然能够识别它们。例如:
1 | |
注解混淆
不想混淆的类需要一个个添加到 proguard-rules. pro (或 proguard. cfg) 中吗?这样会导致 proguard 配置文件变得杂乱无章,同时需要团队所有成员对其语法有所了解。
解决方法1:
1 | |
NotProguard 是个编译时注解,不会对运行时性能有任何影响。可修饰类、方法、构造函数、属性。
然后在 Proguard 配置文件中过滤被这个注解修饰的元素,表示不混淆被 NotProguard 修饰的类、属性和方法。
1 | |
解决方法2:
1 | |
问题不是自己 app,怎么解决
bugly 报的很多问题不是自己 app 的类,怎么解决
第三方库或依赖项:Bugly 可以报告与您的应用程序相关的第三方库或依赖项中出现的问题。这可能是由于库本身的 bug、版本不兼容或配置错误等原因引起的。在这种情况下,您可以尝试更新相关的库版本,查看是否已经发布了修复此问题的更新版本。另外,您还可以尝试搜索相关问题的解决方案或在开发者社区中提问以获得帮助。
系统组件或操作系统问题:有时 Bugly 报告的问题可能涉及到 Android 系统组件或操作系统本身的问题。这可能是由于特定设备、Android 版本或其他环境因素导致的。在这种情况下,您可以尝试查看 Bugly 提供的详细信息,例如堆栈跟踪、设备信息等,以了解问题发生的背景。然后,您可以尝试在 Bugly 或其他社区中搜索相关问题,看是否有其他开发者遇到过类似问题,并找到解决方案或工作回避方法。
混淆和符号化:如果您在应用程序中使用了代码混淆(如 ProGuard)并启用了符号化配置,Bugly 报告的问题可能显示的是混淆后的类名或方法名。在这种情况下,您可以尝试使用符号化映射文件(mapping file)将混淆后的类名还原为原始的类名,以便更好地理解问题出现的位置和上下文。您可以通过在 Bugly 控制台中上传符号化映射文件来实现这一点。
符号化映射文件
将应用程序的崩溃堆栈信息转换为可读形式的文件。它包含了应用程序的符号表(Symbol Table)信息,将编译后的函数和变量名映射回原始的源代码符号,使得崩溃日志更易于理解和分析。
符号化映射文件通常在应用程序构建过程中生成,并与应用程序的发布版本一起打包。在 Android 开发中,常用的构建工具如 ProGuard 或 R8 可以生成符号化映射文件。该文件通常具有 “.mapping” 或 “.txt” 的扩展名。
需要注意的是,符号化映射文件包含敏感信息,如函数名和行号等。因此,为了保护应用程序的安全,符号化映射文件应妥善管理,并不应该随意公开或共享。
Mapping 文件的默认位置为 app/build/outputs/mapping/release/mapping.txt
卡顿优化
卡顿的原因
频繁 GC 造成卡顿、物理内存不足时系统会触发 low memory killer 机制,系统负载过高是造成卡顿的俩个原因。用时分配,及时释放
大部分的卡顿问题都比较好定位,例如主线程执行一个耗时任务、读一个非常大的文件或者是执行网络请求等。
Android 端采用 Matrix 来整理和汇总数据, 同步到实时监控日志
Traceview、systrace 以及 AS 自带的 Profiler 工具。
[[7.优化工具使用#卡顿监测]]
[[第三方框架源码#BlockCanary原理]]
导致卡顿的原因有很多,比如函数非常耗时、I/O 非常慢、线程间的竞争或者锁等,其实很多时候卡顿问题并不难解决,相较解决来说,更困难的是如何快速发现这些卡顿点,以及通过更多的辅助信息找到真正的卡顿原因。