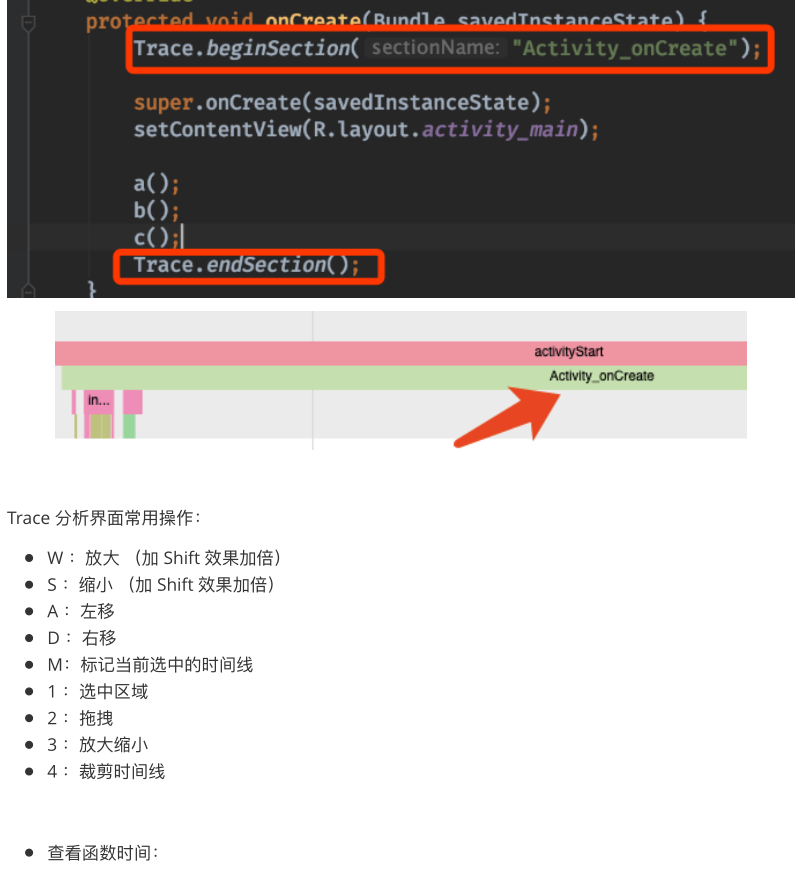
7.优化工具使用
内存泄漏
1 | |
目前栈中所有的Activity的实例,如果数量大于1,说明有内存泄漏的界面。
LeakCanary
App植入LeakCanary之后, 在检测可能的内存泄露后, 会弹出Toast提示,并在桌面生成一个Leaks的icon,点击该icon进入Leaks界面, 可以比较清晰的看到内存泄露疑点。可以看到leak对象的引用关系。
Android 性能优化之利用 LeakCanary 检测内存泄漏及解决办法
Android Profile
打开Android Studio,然后就从android profile(性能分析器)里面观察App的内存使用曲线,突然发现内存使用越来越大了,并且没有回落,就很有可能是发生内存泄漏了。
使用App后在Android Profiler中先触发GC然后dump内存快照(hprof),之后点击按package分类,就可以查看到你的App目前在内存中残留的class,点击class即可在右边查看到对应的实例以及引用对象。按理来说已经被销毁的activity不应该出现在这里
- 强制GC:点击垃圾桶按钮,建议点击后等待几秒后再次点击,尝试多次,让GC更加充分。
- 可以选择某一段区域,在下面就有堆栈信息。
Android 7.1 或更低版本需要记录
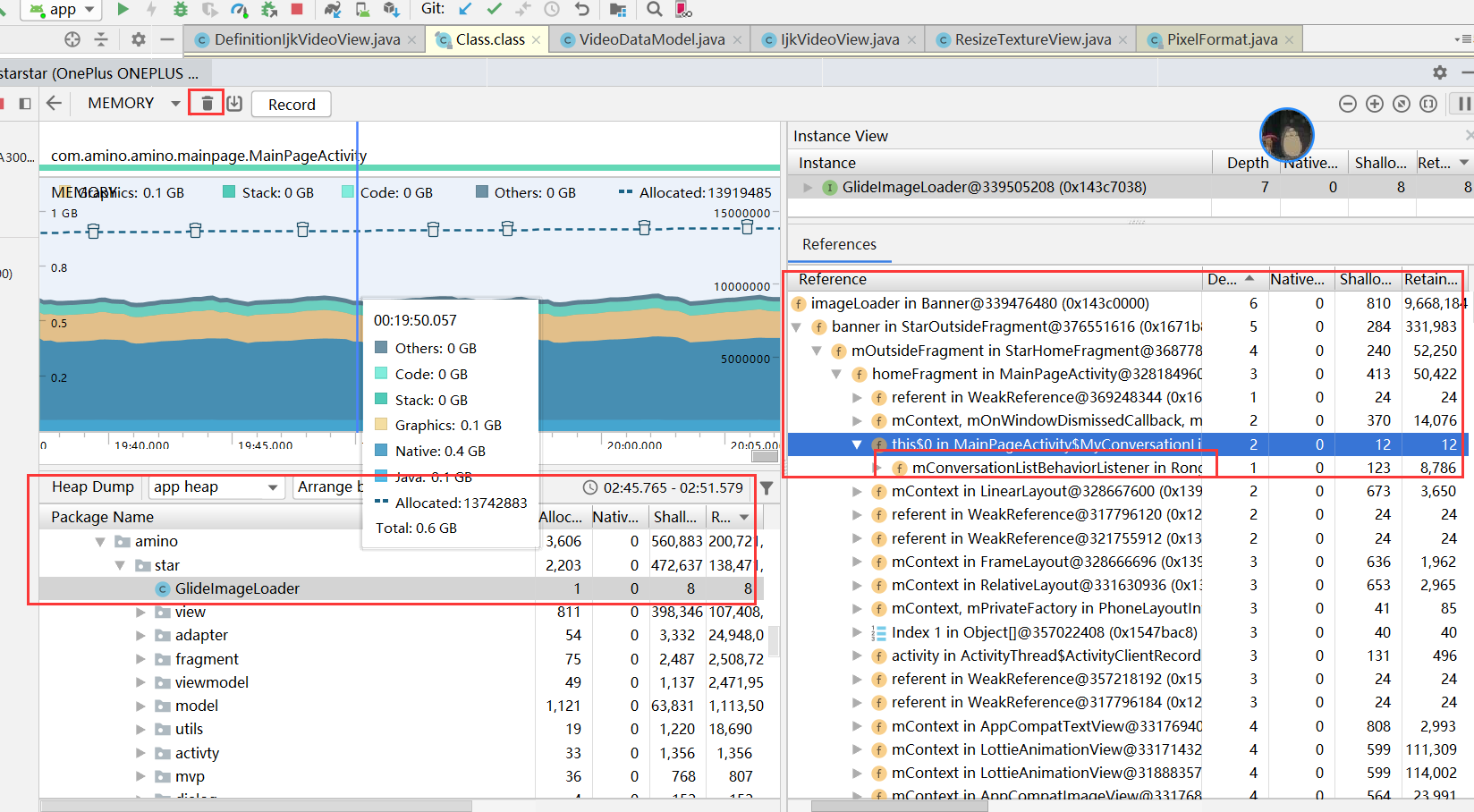
- 堆栈是默认是按Retained Size排序的,Shallow Size指的是该对象本身占用内存的大小,Retained Heap表示这个对象以及它所持有的其它引用(包括直接和间接)所占的总内存,分析内存泄漏时,内存最大的对象也是最应该去怀疑的
- 根据引用关系就可以知道是谁让这个leak的activity活着的, 然后可以 jump to source
- 此例中, 比较简单, 可以很清晰看到是ListenerManager的静态单例sInstance最终支配了MemoryLeakActivity. sIntance连接到GC Roots, 故而导致MemoryLeakActivity GC Roots可达, 无法被回收.
- 上述步骤, 可以让我们快速定位可能的内存泄露. 当然, 内存问题除了内存泄露, 还可以看哪个
内存消耗大。 - bitmap特别大时点开看看图片的宽高是不是有特比大的
在某个页面gc后不在这个页面的view或者activity、fragment不应该出现在堆栈里面,看看是不是有某个东西引用的他们
捕获堆转储
使用:点击 Dump Java heap

| 名称 | 意义 |
|---|---|
| Total Count | 内存中该类的对象个数 |
| Heap Count Count | 堆内存中该类的对象个数 |
| Sizeof | 物理大小 |
| Shallow size | 对象本身占有内存大小 |
| Retained Size | 释放该对象后,节省的内存大小 |
| depth | 深度 |
| Dominating Size | 管辖的内存大小 |
分析内存的技巧
使用 Memory Profiler 时,您应对应用代码施加压力并尝试强制内存泄漏。 在应用中引发内存泄漏的一种方式是,先让其运行一段时间,然后再检查堆。 泄漏在堆中可能逐渐汇聚到分配顶部。 不过,泄漏越小,您越需要运行更长时间的应用才能看到泄漏。
您还可以通过以下方式之一触发内存泄漏:
- 将设备从纵向旋转为横向,然后在不同的 Activity 状态下反复操作多次。 旋转设备经常会导致应用泄漏 Activity、Context 或 View 对象,因为系统会重新创建 Activity,而如果您的应用在其他地方保持对这些对象之一的引用,系统将无法对其进行垃圾回收。
- 处于不同的 Activity 状态时,在您的应用与另一个应用之间切换(导航到主屏幕,然后返回到您的应用)。
分析步骤:
- 不断在手机上操作一个功能,如果该数据在不断地增加,每次GC后没有明显的回落,则判定该功能模块存在内存泄露问题。
- 如果反复操作该功能之后,有一定范围的起伏,但是又被稳定在某一个有限的范围内,则说明代码良好,没有造成对象不被垃圾回收的情况,所以说虽然我们不断的操作会不断的生成很多对象,而在虚拟机不断的进行GC的过程中,这些对象都被回收了,内存占用量会会落到一个稳定的水平;
- 如果有效内存,手机可能会出现程序被kill,但是程序被kill并不能代表程序一定有内存泄露。
- 横竖屏切换,看内存是回落,没有的话这里存在内存泄漏
常见内存泄漏
在您的堆转储中,请注意由下列任意情况引起的内存泄漏:
- 长时间引用Activity、Context、View、Drawable 和其他对象,可能会保持对 Activity 或 Context 容器的引用。
- 可以保持 Activity 实例的非静态内部类,如 Runnable。
- 对象保持时间超出所需时间的缓存。
手动设置 null,解除引用关系
Lint 外,还有像 FindBugs 、 Checkstyle 等静态代码分析工具,主要就静态对象或变量引用着的实例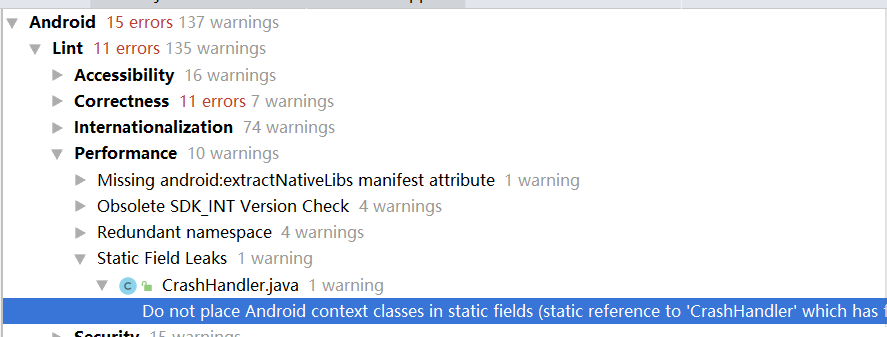
sampling模式和instrumentation模式的区别
两者的区别:
- 在sampling模式中,profiler以固定的间隔对运行中的程序进行采样,根据采样结果统计出程序中各个部分的开销。
- 在instrumentation模式中,profiler对运行中的程序所执行的每一个指令都进行记录,最后根据这份记录生成程序中各个部分的开销。
在实际使用中:
- sampling模式速度快,记录产生的数据量小,但是统计结果并不十分精确,适合于对程序全局性能进行初步的分析,找出程序瓶颈大致的“区间”。
- instrumentation模式能精确记录程序各个部分的开销,但是速度慢,记录产生的数据量大,适合于对程序局部进行精细分析,精确定位瓶颈位置。
实例
- 在内存里发现两个极少概率出现的empty view,占用了很大的内存:用ViewStub对empty view做了懒加载,对于这些没有马上用到的资源要做延迟加载,还有很多大概率不会出现的View更加要做懒加载。 -2M
- 发现详情页的轮播大图的Viewpager用的Adapter是FragmentPagerAdapter,导致了所有的page都会被保存,当图片页数多的时候,往后翻内存会不断上升。优化:这种页数多的ViewPager使用FragmentStatePagerAdapter来替代,它只会保留前后pager,在页数多的时候可以 节省大量内存。
- 遇到个问题,设置显示图片的时候传了dp,可是传了一个像素。会进行俩次算像素,看内存会出现有个特别的大的。
Memory Analyzer(MAT)
内存泄漏不像闪退的BUG,排查起来相对要比较困难些
- 当内存泄漏发生时,LeakCanary 会弹窗提示并生成对应的堆存储信息记录,这让我们对隐蔽的内存泄漏问题有了更加直观的感觉,但从实际使用来看,LeakCanary 的每个提示也并非是真正存在内存泄漏问题,要想确定是否存在问题我们还需要借助 MAT 来进行最后的确定。
- Android 系统本身就存在一些问题导致应用内存泄漏,LeakCanary 的 AndroidExcludedRefs 类帮助我们处理了不少这类问题。
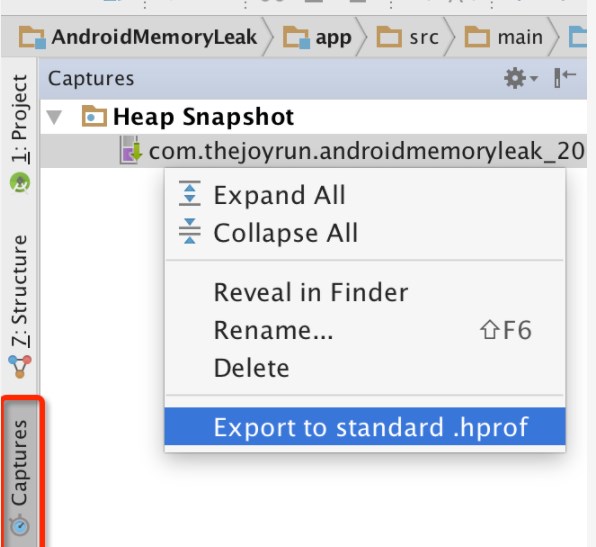
生成的 Heap 文件不是标准的 Java Heap,所以 MAT 无法打开,我们需要转换成标准的 Java Heap 文件,这个工具 Android Studio 就有提供,叫做 Captures,右击选中的 hprof,Export to standard .hprof 选择保存的位置,即可生成一个标准的 hprof 文件。
卡顿监测
perfetto
[[perfetto]]
Traceview
它利用 Android Runtime 函数调用的 event 事件,将函数运行的耗时和调用关系写入 trace 文件中。它可以用来查看整个过程有哪些函数调用,但是工具本身带来的性能开销过大,有时无法反映真实的情况。比如一个函数本身的耗时是 1 秒,开启 Traceview 后可能会变成 5 秒,而且这些函数的耗时变化并不是成比例放大。
在 Android 5.0 之后,新增了 startMethodTracingSampling 方法,可以使用基于样本的方式进行分析,以减少分析对运行时的性能影响
Traceview 此工具已弃用
要检查通过使用 Debug 类检测您的应用而捕获的 . trace 文件、记录新方法跟踪、导出 . trace 文件以及检查应用进程的实时 CPU 使用情况,请使用 Android Studio CPU Profiler。
Hierarchy Viewer
如果要在运行时检查应用的视图层次结构,请使用 Layout Inspector。如果您要分析应用布局的渲染速度,请使用 Window. OnFrameMetricsAvailableListener,如本博文中所述。
获取方法运行时间
matrix trace canary
1 | |
CPU Profiler
操作前点记录,完了点stop,会生成下面的
一般看红色,蓝色是自己的代码的方法的耗时,红色时间长
特点
找到最耗费时间的路径:Flame Chart、Top Down。
找到最耗费时间的节点:Bottom Up。
CPU 时间轴
显示应用的实时 CPU 使用率(以占总可用 CPU 时间的百分比表示)以及应用当前使用的线程总数。此时间轴还显示其他进程(如系统进程或其他应用)的 CPU 使用率,以便您可以将其与您应用的使用率进行对比。您可以通过沿时间轴的水平轴移动鼠标来检查历史 CPU 使用率数据。

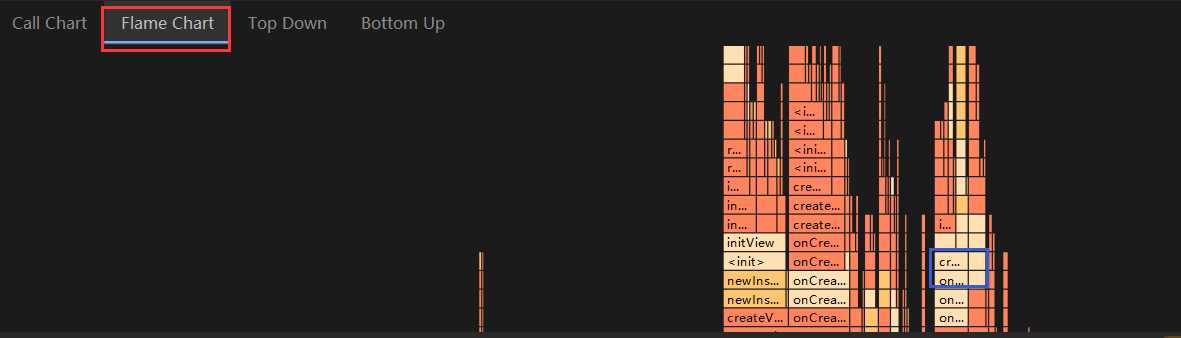
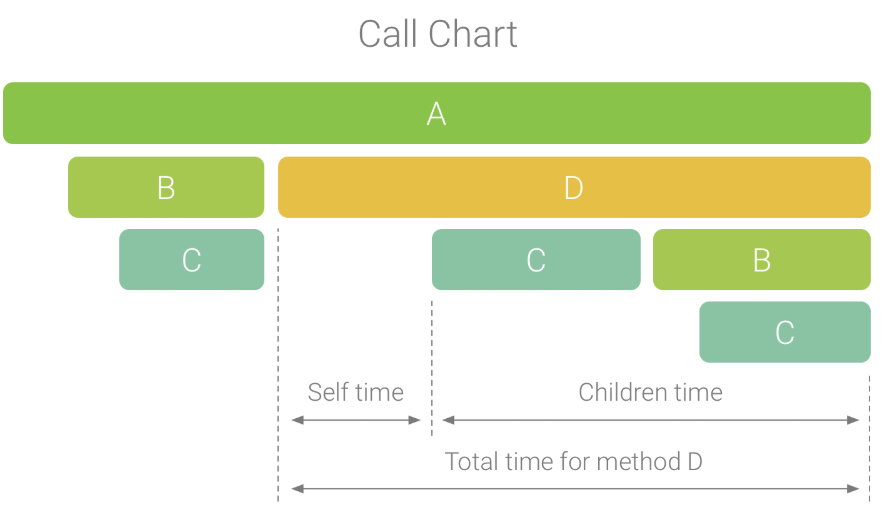
Call Chart
Flame Chart
Flame Chart 标签提供一个倒置的调用图表,用来汇总完全相同的调用堆栈。也就是说,将具有相同调用方顺序的完全相同的方法或函数收集起来,并在火焰图中将它们表示为一个较长的横条(而不是将它们显示为多个较短的横条,如调用图表中所示)。这样更方便您查看哪些方法或函数消耗的时间最多。不过,这也意味着,水平轴不代表时间轴,而是表示执行每个方法或函数所需的相对时间量。
注意,方法 D 多次调用 B(B1、B2 和 B3),其中一些对 B 的调用也调用了 C(C1 和 C3)。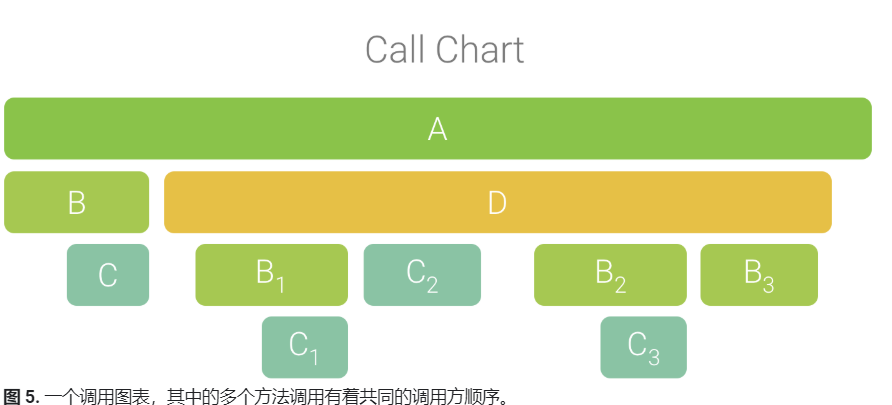
使用“Top Down”和“Bottom Up”检查跟踪数据
Top Down 标签显示一个调用列表,在该列表中展开方法或函数节点会显示它的被调用方。图 8 显示了图 4 中调用图表的自上而下图。图中的每个箭头都从调用方指向被调用方。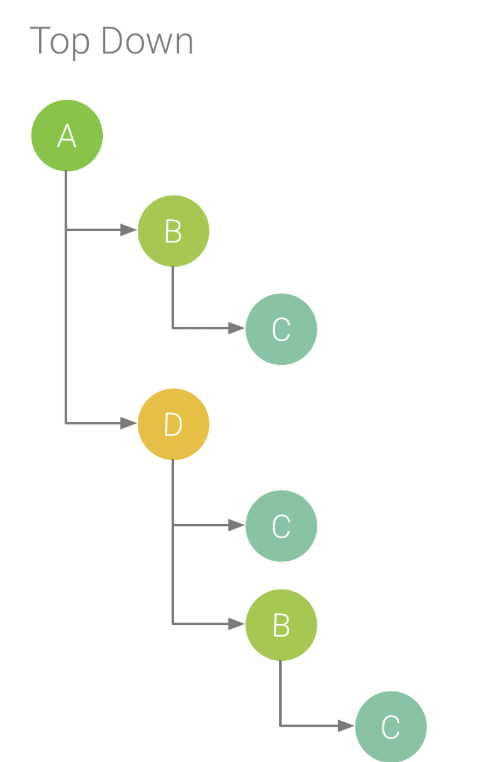
Bottom Up标签用于按照消耗的 CPU 时间由多到少(或由少到多)的排序对方法或函数排序。您可以检查每个节点以确定哪些调用方在调用这些方法或函数上所花的 CPU 时间最多
检查帧渲染数据
您可以检查应用在主线程和 RenderThread 上渲染每个帧所用的时间,以调查导致界面卡顿和帧速率较低的瓶颈。要查看帧渲染数据,请使用可让您跟踪系统调用的配置记录跟踪数据。记录跟踪数据后,在名为 FRAMES 的部分下查找有关每个帧的信息
每个所用时间超过 16 毫秒的帧都以红色显示。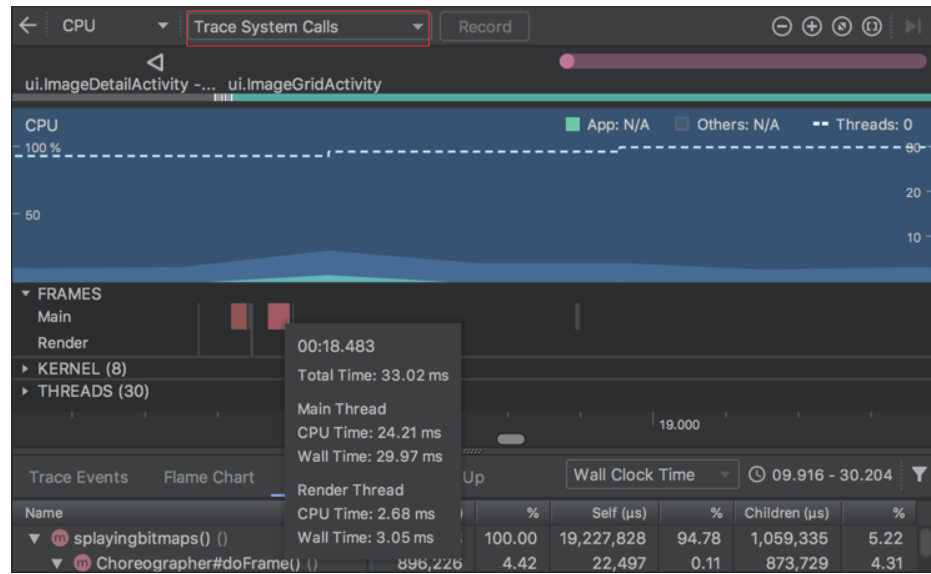
Systrace
使⽤ python 终端命令⽣成 Trace ⽂件 官⽅⽂档
在⾼版本中,可以通过 System tracing ⽣成 trace ⽂件,⽣成的⽂件可以在 这⾥ 在线分析
在代码中主动做标记