Flow学习
LiveData的不足
LiveData结构简单,但是不够强大,它有以下不足
- LiveData不支持线程切换,所有数据转换都将在主线程上完成,有时需要频繁更改线程,面对复杂数据流时处理起来比较麻烦
- LiveData的操作符不够强大,在处理复杂数据流时有些捉襟见肘
- LiveData 只能在主线程更新数据: 只能在主线程 setValue,即使 postValue 内部也是切换到主线程执行;
- LiveData 数据重放问题: 注册新的订阅者,会重新收到 LiveData 存储的数据,这在有些情况下不符合预期(可以使用自定义的 LiveData 子类 SingleLiveData 或 UnPeekLiveData 解决,此处不展开);
- LiveData 不防抖: 重复 setValue 相同的值,订阅者会收到多次 onChanged() 回调(可以使用 distinctUntilChanged() 解决,此处不展开);
- LiveData 不支持背压: 在数据生产速度 > 数据消费速度时,LiveData 无法正常处理。比如在子线程大量 postValue 数据但主线程消费跟不上时,中间就会有一部分数据被忽略。
- Flow可以跟LiveData结合使用,LiveData的生命周期在OnDestory前不会自动取消订阅,在一些UI相关场景没有问题,可以使用LiveData。Flow则更加强大,可以在onPause等时机中止上游流,节省资源。
Flow,LiveData说白了都是观察者模式,在ViewModel中生产数据,在View中观察数据,Flow生产数据时不用切换线程,LiveData生产数据时会切换到主线程,这就是区别。
Flow 支持数据重放配置: Flow 的子类 SharedFlow 支持配置重放
replay:能够自定义对新订阅者重放数据的配置
好文章
有小伙伴说看不懂 LiveData、Flow、Channel,跟我走
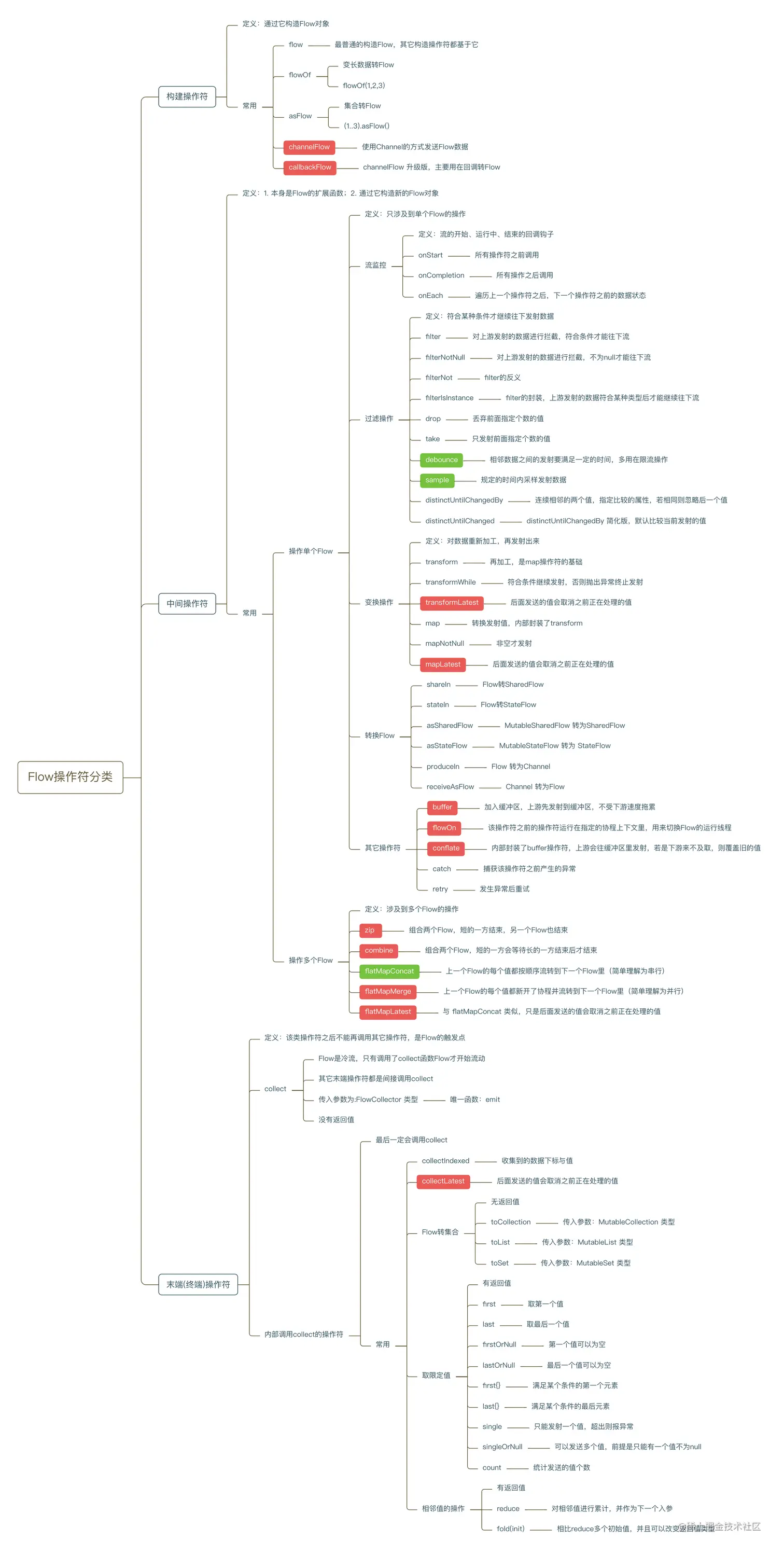
Flow
用法:使用flow {…} 函数创建了一个冷数据流Flow,通过emit来发射数据,然后通过collect函数来收集这些数据
1 | |
线程切换
- flowOn只影响前面没有自己上下文的操作符。已经有上下文的操作符不受后面flowOn影响。
- 不管 flowOn 如何切换线程, collect 始终是运行在调用它的协程调度器上。
- flowOn 下一行开始生效
1 | |
常用操作符
过度操作符:又或者叫做流程操作符,用来区分流程执行到某一个阶段。比如:onStart/onEach/onCompletion。过渡操作符应用于上游流,并返回下游流。这些操作符也是冷操作符,就像流一样。这类操作符本身不是挂起函数。它运行的速度很快,返回新的转换流的定义。异常操作符:用来捕获处理流的异常。比如:catch,onErrorCollect(已废弃,建议用catch)。
转换操作符:主要做一些数据转换操作。比如:transform/map/filter/flatMapConcat等
限制操作符:流触及相应限制的时候会将它的执行取消。比如:drop/take等
末端操作符:是在流上用于启动流收集挂起函数。==collect 是最基础的末端操作符==,但是还有另外一些更方便使用的末端操作符。例如:toList、toSet、first、single、reduce、fold等等
1 | |
D/carman: collect :1 :one
D/carman: collect :2 :two
D/carman: collect :3 :three
直接使用Flow的局限性
虽然Flow可以将任意的对象转换成流的形式进行收集后计算结果。但是如果我们是直接使用Flow,它一次流的收集是我们已知需要计算的值,而且它每次收集完以后就会立即销毁。我们也不能在后续的使用中,发射新的值到该流中进行计算。
为什么要使用 StateFlow 和 ShareFlow?
[[冷流热流]]
我们希望状态的变动都能通知到会有所动作的观察者。
StateFlow和ShareFlow也是Flow API的一部分,它们允许数据流以最优方式,发出状态更新并向多个使用方发出值。
与使用flow构建器构建的冷数据流不同,StateFlow是热数据流。
StateFlow是继承自SharedFlow,我们可以把StateFlow看作为SharedFlow一个更佳具体实现。
操作符
buffer
有个需求:上游发射数据速度高于下游,如何提升发射效率?
使用buffer操作符解决背压问题
buffer原理简单来说:
构造了新的协程执行flow闭包,上游数据会发送到Channel 缓冲区里,发送完成继续发送下一条
collect操作符监听缓冲区是否有数据,若有则收集成功
原理是基于ChannelFlow
上游生产速度很快,下游消费速度慢,我们只关心最新数据,旧的数据没价值可以丢掉。 使用conflate操作符处理