1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
| content = '333STR1666STR299'
regex = r'([A-Z]+(\d))'
print(re.match(regex, content))
match = re.search(regex, content)
print('\nre.search() return value: ' + str(type(match)))
print(match.group(0), match.group(1), match.group(2))
result1 = re.findall(regex, content)
print('\nre.findall() return value: ' + str(type(result1)))
for m in result1:
print(m[0], m[1])
result2 = re.finditer(regex, content)
print('\nre.finditer() return value: ' + str(type(result2)))
for m in result2:
print(m.group(0), m.group(1), m.group(2))
print re.match(r'^\d{3}\-\d{3,8}
, '010-12345')
# _sre.SRE_Match object at 0x1026e18b8>
print re.match(r'^\d{3}\-\d{3,8}
, '010 12345')
print re.split(r'\s+', 'a b c')
print re.split(r'[\s\,]+', 'a,b, c d')
print re.split(r'[\s\,\;]+', 'a b;; c d')
m = re.match(r'^(\d{3})-(\d{3,8})
, '010-12345')
print m.group(0)
print m.group(1)
print m.group(2)
t = '19:05:30'
m = re.match(
r'^(0[0-9]|1[0-9]|2[0-3]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])\:(0[0-9]|1[0-9]|2[0-9]|3[0-9]|4[0-9]|5[0-9]|[0-9])
,
t)
print m.groups()
print re.match(r'^(\d+)(0*)
, '102300').groups()
# ('102300', '')
# 由于\d+采用贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串了。
# 必须让\d+采用非贪婪匹配(也就是尽可能少匹配),才能把后面的0匹配出来,加个?就可以让\d+采用非贪婪匹配:
print re.match(r'^(\d+?)(0*)
, '102300').groups()
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})
)
# 使用:
print re_telephone.match('010-12345').groups()
# ('010', '12345')
print re_telephone.match('010-8086').groups()
# ('010', '8086')
# someone@gmail.com
# <Tom Paris> tom@voyager.org
# 正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,
# 它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
# 如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,
# 正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
a = '''asdfhellopass:
123
worldaf
'''
b = re.findall('hello(.*?)world', a)
c = re.findall('hello(.*?)world', a, re.S)
print 'b is ', b
print 'c is ', c
# b is []
# c is ['pass:\n\t123\n\t']
text = ''
file = open('sina.html')
for line in file:
text = text + line
file.close()
# {}表示位数,[][]表示第一位第二位
# ()是或者,几个()就是几个元素的数组,没有会是"",所以过滤了下
# match和findall的区别
# 1).*? 是一个固定的搭配,.和*代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,
# 也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
# 2)(.*?)代表一个分组,在这个正则表达式中我们匹配了五个分组,在后面的遍历item中,
# item[0]就代表第一个(.*?)所指代的内容,item[1]就代表第二个(.*?)所指代的内容,以此类推。
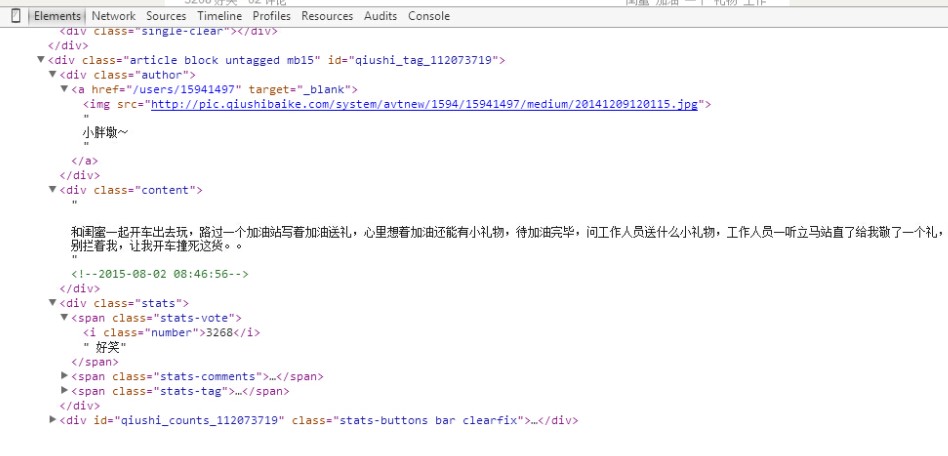
pattern = re.compile(
'<div class="author clearfix">.*?<a.*?<h2>(.*?)</h2>.*?<div class="articleGender manIcon">(.*?)</div>.*?<div class="content">.*?<span>(.*?)</span>.*?<span class="stats-vote"><i class="number">(.*?)</i>',
re.S)
items = re.findall(pattern, text)
for item in items:
print item
# final_result = set()
# for pair in result:
# if pair[0] not in final_result:
# final_result.add(pair[0])
# if pair[1] not in final_result:
# final_result.add(pair[1])
#
# final_result.remove('')
# print(final_result)
print items
|