泛型
在没有泛型之前,从集合读取到的每一个对象都必须进行转换,如果有人不小心插入了类型错误的对象,在运行的转换处理就会出错。有了泛型之后,可以告诉编译器每个集合中接受哪些对象类型。编译器自动为你的插入进行转化,并在编译时告知是否插入了类型错误的对象,这样更安全,也更清楚。
其他好处
为了限制功能,例如 list 里必须统一类型的数据,类型安全,省去转型了。
或者抽象代码,限制后期只能存放某一类数据
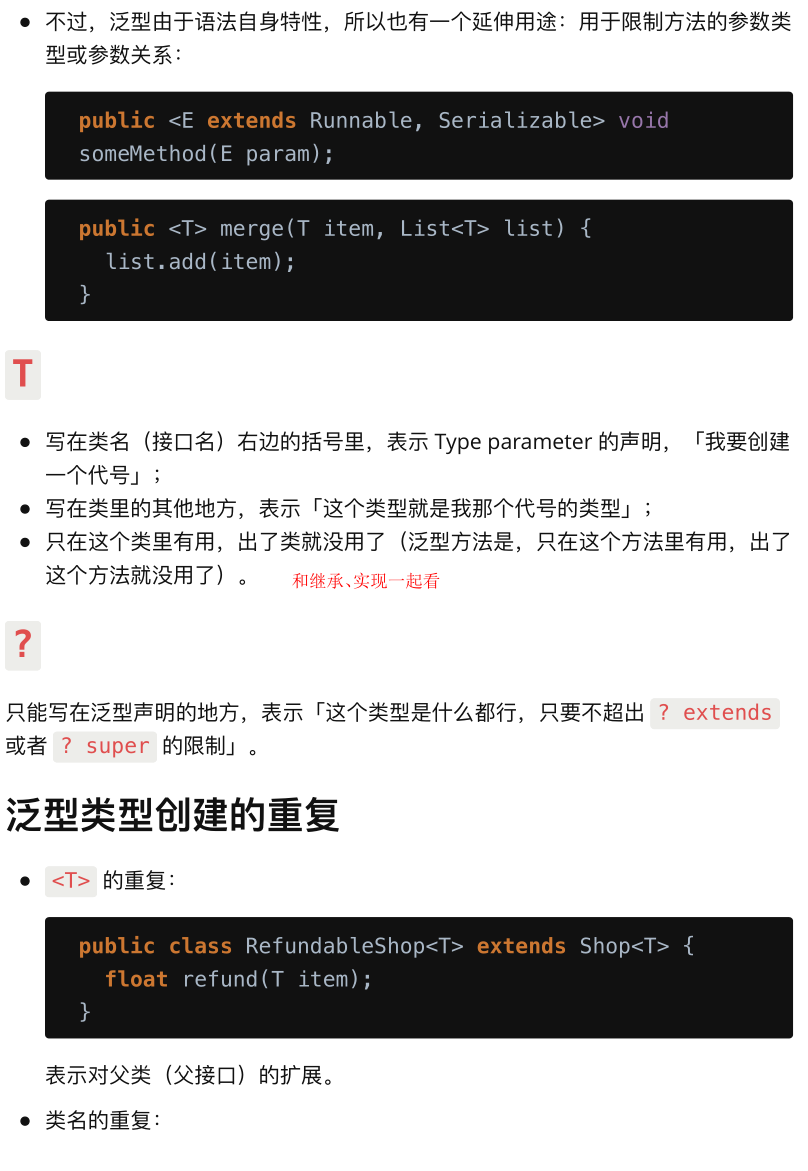
同一个方法的参数必须是某一个或者另一个类的子类,也可以同时(泛型方法)
1
| public <E extends Runnable, Serializable> void someMethod(E param);
|
泛型的创建者让泛型的使用者可以在使用时(实例化时)细化类型信息,从而可以触及到「使用者所细化的⼦类」的 API。或者,泛型是「有远见的创造者」创造的「方便使用者」的工具
泛型方法
说明:
- public 与返回值中间<\T>非常重要,可以理解为声明此方法为泛型方法。
- 只有声明了<\T>的方法才是泛型方法,泛型类中的使用了泛型的成员方法并不是泛型方法。
- <\T>表明该方法将使用泛型类型 T,此时才可以在方法中使用泛型类型 T。
- 与泛型类的定义一样,此处 T 可以随便写为任意标识,常见的如 T、E、K、V 等形式的参数常用于表示泛型。
1
2
3
4
5
6
7
8
9
10
| /**
* @param tClass 传入的泛型实参
* @return T 返回值为T类型
*/
public <T> T genericMethod(Class<T> tClass)throws InstantiationException ,
IllegalAccessException{
T instance = tClass.newInstance();
return instance;
}
|
实例
通过使用方法按步骤看哪可以抽象
例如网络请求要封装,例如 OKHTTP 用起来还是挺麻烦,每次都写那么一堆显示不合理,可以把请求的 host、path、请求参数、返回结果封装起来。然后返回结果数据都差不多,都有 errro_code、error_msg、data,data 就可以使用泛型、data 又有 list 和不是 list 的,又可以使用泛型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class MyHttpResponse<T> {
private int code;
private String msg;
private T data;
}
public class ListBean<T> {
private int total;
private ArrayList<T> list;
}
Flowable<MyHttpResponse<ListBean<MyRecordBean>>> voiceList(@Query("offset") int offset);
Flowable<MyHttpResponse<TaskStatusBean>> getTaskInfo(@Query("classCode") String classCode);
|
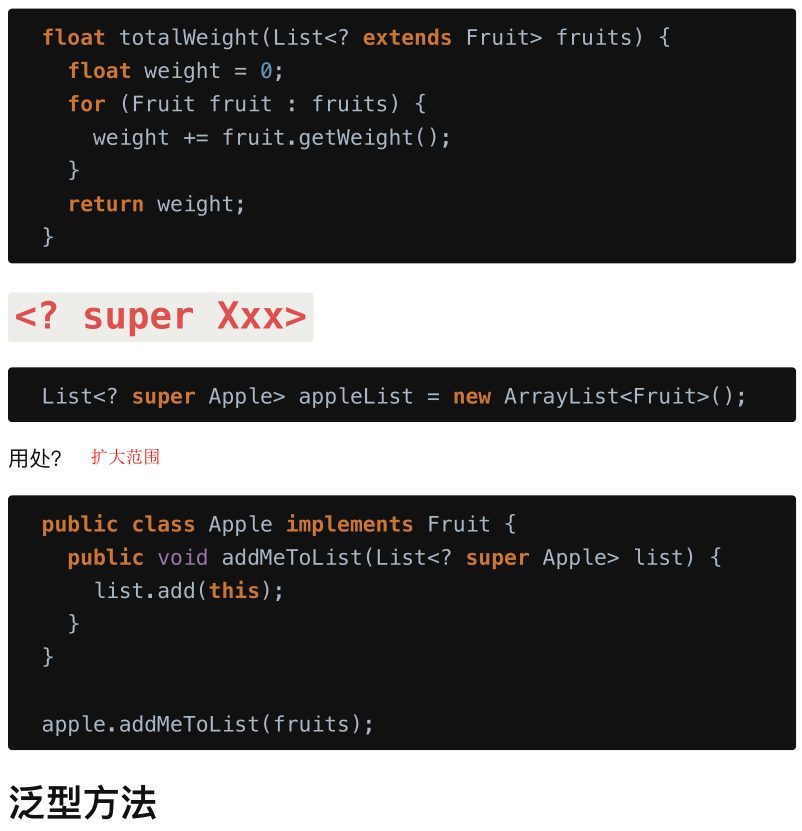
super 和 extends
? entends E: 接收 E 类型或者 E 的子类型对象
? super E: 接收 E 类型或者 E 的父类,扩大范围
存
1
2
3
4
5
6
7
8
9
10
11
12
| Apple apple = new Apple();
List<Apple> apples = new ArrayList<Apple>(){};
List<Fruit> fruits = new ArrayList<Fruit>(){};
apple.addMeToList(apples);
apple.addMeToList(fruits);
public class Apple implements Fruit {
public void addMeToList(List<? super Apple> list) {
list.add(this);
}
}
apple.addMeToList(fruits);
|
可以获取,, 看下面
1
2
3
4
5
6
7
8
9
10
11
12
13
| List<Fruit> fruits = new ArrayList<>();
fruits.add(new Apple());
fruits.add(new Banana());
float fruitsWeight = totalWeight(fruits);
public float totalWeight(List<? extends Fruit> fruits) {
float weight = 0;
for (Fruit fruit : fruits) {
weight += fruit.weight();
}
return weight;
}
|
另一种
1
2
3
|
List<? extends Fruit> fruits = new ArrayList<Apple>();
List<? super Apple> apples = new ArrayList<Fruit>();
|

泛型擦除
在 Java 中,泛型是在 JDK 5.0引入的新特性。为了确保新版本的 Java 与旧版本的代码兼容,设计者决定在编译后将泛型信息擦除,这样可以确保使用泛型的新代码可以与不使用泛型的旧代码进行互操作。
具体来说,当编译器处理泛型类型时,它会将泛型类型转换为原始类型,并插入必要的强制类型转换以确保类型安全。这个过程就是所谓的“类型擦除”。因此,尽管我们在编写源代码时使用了泛型,但在生成的字节码中,泛型信息已经被擦除了。
假设我们有一个简单的泛型类 Box,如下所示:
1
2
3
4
5
6
7
8
9
10
11
| public class Box<T> {
private T value;
public void setValue(T value) {
this.value = value;
}
public T getValue() {
return value;
}
}
|
当我们使用这个泛型类创建对象并调用方法时,编译器会进行类型擦除。例如:
1
2
3
4
| Box<Integer> integerBox = new Box<>()
integerBox.setValue(10)
Integer intValue = integerBox.getValue()
|
在编译后,上述代码中的泛型信息将被擦除,转换为如下的非泛型代码:
1
2
3
4
| Box integerBox = new Box()
integerBox.setValue(10)
Integer intValue = (Integer) integerBox.getValue()
|
在这里,泛型信息 <Integer> 被擦除,编译器在生成的字节码中插入了强制类型转换 (Integer) 来确保类型安全。这样即可保证运行时的类型安全性,并与旧版本的 Java 代码兼容。
泛型在编译期会被擦除的概念,那么为什么我们在运行时还能读取到呢?
把例如 T 这类东西擦除(为了兼容旧版本)
泛型的使用只是为了我们编写代码时,省去了强制转换,其实最终还是会强转成对应类型的,把代码设置成实际设置值
通过反射,我们可以获取类的参数化类型,并对其进行操作。Java 中提供了一些 API,如 ParameterizedType,用于在运行时获取泛型信息。利用这些 API,我们可以在运行时对泛型进行操作,例如获取泛型类型、泛型参数等信息。
1
| this.getClass().getGenericSuperclass();
|
泛型接口

其他