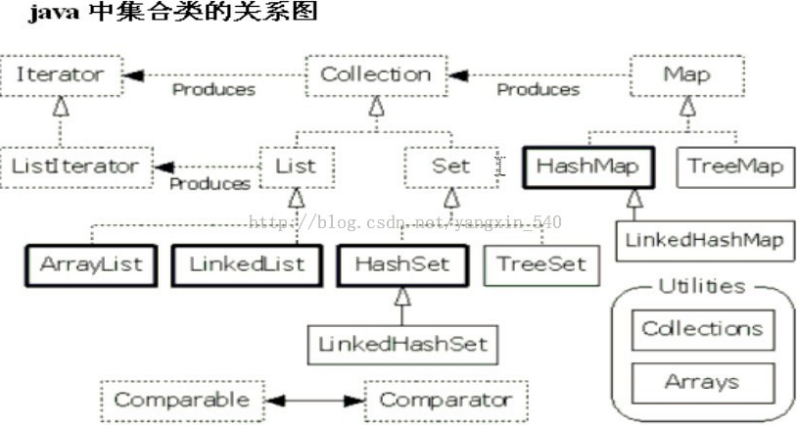
Java集合
集合
List、Set、Map是否继承自Collection接口? (也叫容器类)
List、Set 是,Map 不是。Map是键值对映射容器双列集合,Collection是单列集合,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形。
Collection 和 Map 的区别
Collection:单列集合,一次存一个元素
Map:双列集合,一次存一对集合,两个元素(对象)存在着映射关系
ArrayList、LinkedList的存储性能和特性
- ArrayList 和 Vector 都是使用数组方式存储数据(不是连续),此数组元素数大于实际存储的数据以便增加和插入元素,它们都允许直接按序号索引元素,但是插入元素要涉及数组元素移动等内存操作,所以索引数据快而插入数据慢据慢
- LinkedList使用双向链表实现存储(将内存中零散的内存单元通过附加的引用关联起来,形成一个可以按序号索引的线性结构,这种链式存储方式与数组的连续存储方式相比,内存的利用率更高),按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
- 由于ArrayList和LinkedListed都是非线程安全的,如果遇到多个线程操作同一个容器的场景,则可以通过工具类Collections中的synchronizedList方法将其转换成线程安全的容器后再使用(这是对装饰模式的应用,将已有对象传入另一个类的构造器中创建新的对象来增强实现)。
源码
1 | |
Vector 通过synchronized 保证线程安全
1 | |
技巧
需要唯一吗?
- 需要:Set
需要制定顺序:
需要: TreeSet(指定方式排序)
不需要:HashSet
但是想要一个和存储一致的顺序(有序:怎么存怎么取):LinkedHashSet - 不需要:List
需要频繁增删吗?
需要:LinkedList
不需要:ArrayList
如何记录每一个容器的结构和所属体系呢?
看名字!后缀名就是该集合所属的体系。前缀名就是该集合的数据结构。
看到array:就要想到数组,就要想到查询快,有角标.
看到link:就要想到链表,就要想到增删快,就要想要 add get remove+frist last的方法
看到hash:就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashcode方法和equals方法。不能保证元素的排列顺序,顺序有可能发生变化
看到tree:就要想到二叉树,就要想要排序,就要想到两个接口Comparable,Comparator 。判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。通常这些常用的集合容器都是不同步的。
collection和Collections的区别
Collection是一个接口,它是Set、List等容器的父接口;
Collections是个一个工具类,提供了一系列的静态方法来辅助容器操作,这些方法包括对容器的搜索、排序、线程安全化等等。
Collections集合工具类:操作集合(一般是 list 集合)的工具类。方法全为静态的
sort(List list);对 list 集合进行排序;
sort(List list, Comparator c) 按指定比较器排序
fill(List list, T obj);将集合元素替换为指定对象;
swap(List list, int I, int j)交换集合指定位置的元素
shuffle(List list); 随机对集合元素排序
数组和集合相互转换
Arrays:用于操作数组对象的工具类,全为静态方法
asList():将数组转为 list 集合
好处:可通过 list 集合的方法操作数组中的元素:isEmpty()、contains()、indexOf()、set()
弊端:数组长度固定,不可使用集合的增删操作。
集合转为数组:Collection.toArray();
好处:限定了对集合中的元素进行增删操作,只需获取元素
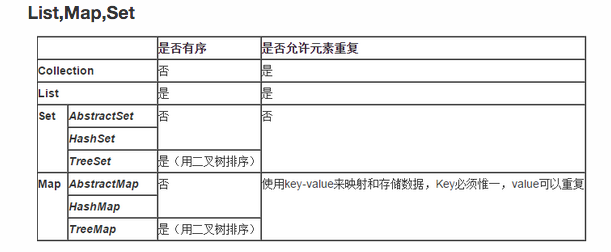
List、Map、Set三个接口存取元素时,各有什么特点?
List以特定索引来存取元素,可以有重复元素。Set不能存放重复元素(用对象的equals()方法来区分元素是否重复)。Map保存键值对(key-value pair)映射,映射关系可以是一对一或多对一。
Set和Map容器都有基于哈希存储和排序树的两种实现版本,基于排序树版本的实现在插入或删除元素时会按照元素或元素的键(key)构成排序树从而达到排序和去重的效果。
Set就是个接口,hashset通过hashmap实现的
- HashSet:对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。(ArrayList只依赖equals)
- TreeSet:底层是二叉树,可对元素进行排序,默认是自然顺序,保证唯一性:Comparable接口的 compareTo方法的返回值
- HashMap:底层数据结构是哈希表;允许使用 null 键和 null 值,这样的键只有一个;可以有一个或多个键所对应的值为null。不同步,效率高
- HashTable:底层数据结构是哈希表,不可存入 null键和 null值。同步的
CopyOnWrite
- CopyOnWrite 容器可以在并发场景中使用。CopyOnWriteArrayList 的效率比 ArrayList 略有下降,空间利用率也下降了很多,但是 CopyOnWriteArrayList 是线程安全的
- 集合容器是不能遍历的时候增删的,会报错 ConcurrentModificationException,防止多个线程同时修改同一个集合的元素。
- CopyOnWriteArrayList就不会报错,它的原理是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是可以对CopyOnWrite容器进行并发的读写,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
- 遍历的时候增删可以使用 Iterator
1 | |
Map
Map集合如何取元素两种获取集合元素的方法
- keySet()方法获取元素原理:将Map集合中的所有键存入到Set集合中,因为Set集合具备迭代器,所以可以用迭代方式取出所有的键,再根据get方法获取每一个键对应的值。简单说就是:Map集合—->Set集合 —->迭代器取出
- entrySet()方法获取元素:(上面有)原理:将Map集合中的映射关系存入到了Set集合中,而这个映射关系的数据类型是Map.Entry(结婚证),在通过迭代器将映射关系存入到Map.Entry集合中,并通过其中的getKey()和getValue()放取出键值。
比较器
TreeMap 和 TreeSet 在排序时如何比较元素?
答:TreeSet要求存放的对象所属的类必须实现Comparable接口,该接口提供了比较元素的compareTo()方法,当插入元素时会回调该方法比较元素的大小。TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。
- 二叉树的存储方式就像树叉一样,所以称为二叉树。而排序树的特点就是把大的数放在右边,小的数放在左边,取值时会按照从小到大的顺序取值。如果数据较多,二叉树会自动折中,然后再去判断,。这样就大大提高了存取的效率。
- 说到排序就俩种,自然排序(实现Comparable接口的)和指定顺序排序。排序的两种实现方式,让元素本身具备比较性(Comparable)和让容器具备比较性(比较器Comparator)。
- TreeSet可以对Set集合中的元素进行排序。底层数据结构是二叉树。保证元素唯一性的依据:compareTo方法return 0。TreeSet存储对象的时候, 可以排序, 但是需要指定排序的算法。Integer能排序(有默认顺序), String能排序(有默认顺序), 自定义的类存储的时候出现异常(没有顺序)。如果想把自定义类的对象存入TreeSet进行排序, 那么必须实现Comparable接口。在类上实现Comparable, 重写compareTo()方法,在方法内定义比较算法, 根据大小关系, 返回正数负数或零,在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较, 根据比较结果使用二叉树形式进行存储。
- TreeSet是依靠TreeMap来实现的。TreeSet是一个有序集合,TreeSet中的元素将按照升序排列(指排序的顺序),缺省是按照自然排序进行排列,意味着TreeSet中的元素要实现Comparable接口。或者有一个自定义的比较器。我们可以在构造TreeSet对象时,传递实现Comparator接口的比较器对象。
让容器具备比较性,定义比较器,将比较器对象作为参数传递给TreeSet集合的构造函数。当两种排序都存在时,以比较器为主。实现方式:定义一个类,实现Comparator接口,覆盖compare方法。
- 需求:对字符串进行按长度排序
- 分析:字符串本身具备比较性,但是是按自然顺序进行的排序,所以需要对排序方式进行重新定义,所以需要让集合具备比较性
- 使用比较器Comparator,覆盖compare 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68public class TestTreeSet {
public static void main(String[] args) {
TreeSet<ComString> ts = new TreeSet<ComString>(new Mycompare());
ts.add(new ComString("asd"));
ts.add(new ComString("df"));
ts.add(new ComString("dk"));
ts.add(new ComString("jkkggd"));
ts.add(new ComString("sfsfssgds"));
Iterator it = ts.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
class Mycompare implements Comparator<ComString> {
public int compare(ComString o1, ComString o2) {
int num = o1.getS().length() - o2.getS().length();
if (num == 0) {
return o1.getS().compareTo(o2.getS());
}
return num;
}
}
class ComString {
private String s;
ComString(String s) {
this.s = s;
}
class ComparatorByName implements Comparator<Perosn> {
public int compare(Person o1,Person o2){
int temp=o1.getName().comparaTo.(o2.getName);
return temp==0? o1.getAge-o2.getAge:temp;
}
}
public class TreeMapDemo {
public static void main(String[] args) {
TreeMap<Student,String> tm = new TreeMap<Student,String>(new ComparatorByName());
tm.put(new Student("lisi",38),"北京");
tm.put(new Student("zhaoliu",24),"上海");
tm.put(new Student("xiaoqiang",31),"沈阳");
tm.put(new Student("wangcai",28),"大连");
tm.put(new Student("zhaoliu",24),"铁岭");
Iterator<Map.Entry<Student, String>> it = tm.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Student,String> me = it.next();
Student key = me.getKey();
String value = me.getValue();
System.out.println(key.getName()+":"+key.getAge()+"---"+value);
}
}
}
Collections.sort(list); 自然排序[abc, bbce, cbcef, dbcefg, ebcefgh]
mySort(list);
mySort(list,new ComparatorByLength());
Collections.sort(list,new ComparatorByLength()); 指定排序(简单)