Serializable 与 Parcelable
序列化
序列化的三种场景:
- 持久化存储
- 通过 Socket 进行网络传输
- 深拷贝
把数据对象(⼀般是内存中的,例如 JVM 中的对象)转换成字节序列的过程。对象在程序内存⾥的存放形式是散乱的(存放在不同的内存区域、并且由引⽤进⾏连接),通过序列化可以把内存中的对象转换成⼀个字节序列,从⽽使⽤ byte[] 等形式进⾏本地存储或⽹络传输,在需要的时候重新组装(反序列化)来使⽤。
把内存中的对象变成二进制形式
⽬的
让内存中的对象可以被储存和传输。
序列化是编码吗?
不是
和编码的区别
编码是把数据由⼀种数据格式转换成另⼀种数据格式;⽽序列化是把数据由内存中的对象(⽽不是某种具体的格式)转换成字节序列。
如何实现序列化,有什么意义
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。
序列化除了能够实现对象的持久化之外,还能够用于对象的深度克隆。
浅拷贝和深拷贝
深拷贝是指在计算机编程中,将一个对象的所有属性和方法复制到另一个对象的过程。
与浅拷贝不同,深拷贝会递归地复制对象的所有子对象,而不仅仅是复制对象的引用
这样,当修改原始对象时,深拷贝的对象不会受到影响,因为它们是独立的副本。
如何实现对象克隆
有两种方式:
- 实现 Cloneable 接口并重写 Object 类中的 clone ()方法;
- 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下:
序列化其实就是将对象封装到本地。用作对象的持久化存储,也就是用流存放到硬盘上,Serializable: 用于给被序列化的类加入 ID 号。
用于判断类和对象是否是同一个版本。静态不能被序列化, transient 关键字修饰的不能被序列化
使用 ByteArrayOutputStream1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
public static <T> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用ByteArrayInputStream或ByteArrayOutputStream对象的close方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
下面是测试代码:
1 | |
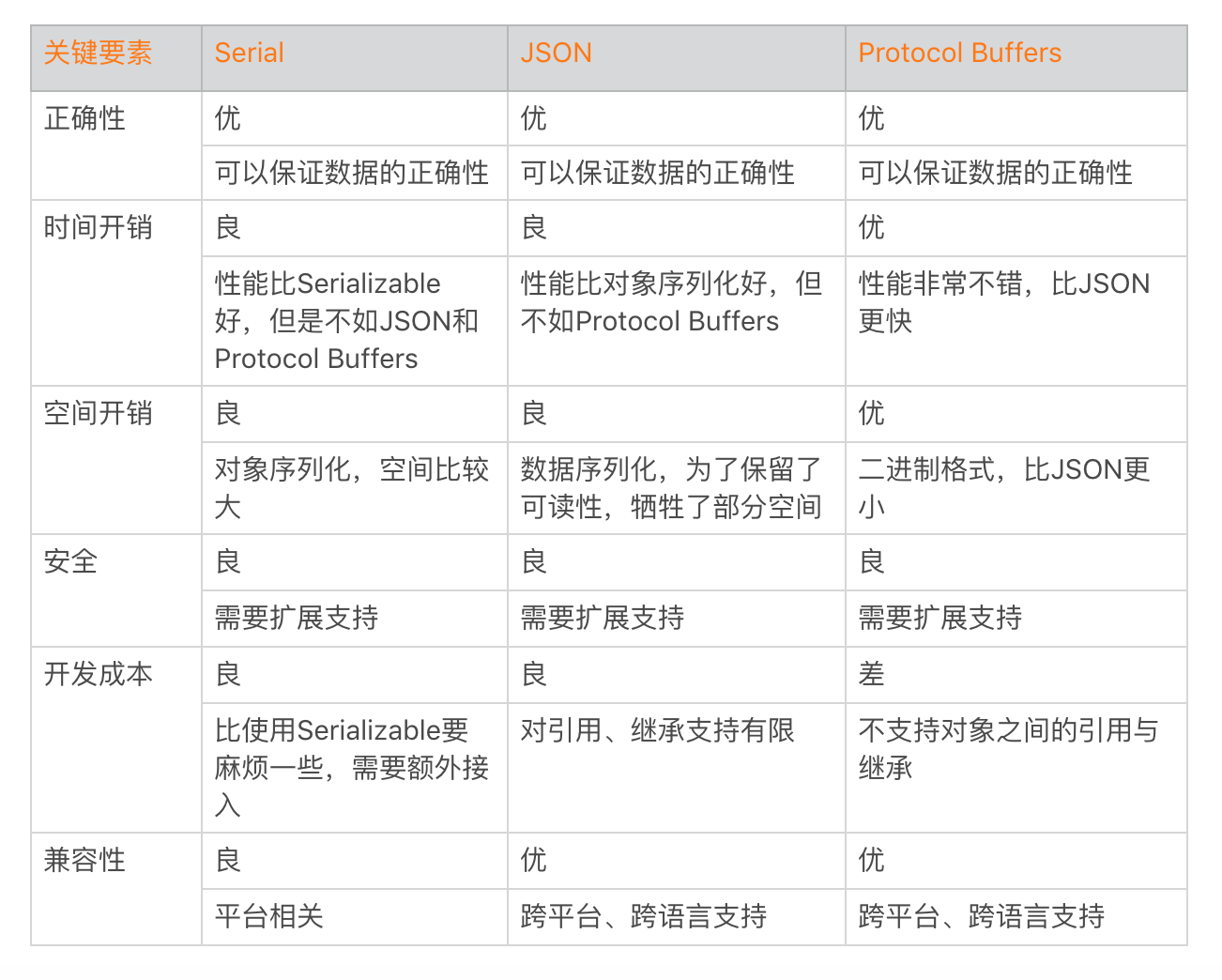
Serializable
Serializable 和 Parcelable 是用来序列化和反序列化的,其中 Serializable 是 Java 提供的一个序列化接口,它是一个空接口,专门为对象提供标准的序列化和反序列化操作,使用起来比较简单。而 Parcelable 则稍显复杂,实现该接口重写两个模版方法,并且需要提供一个 Creator。
- 原理是通过 ObjectInputStream 和 ObjectOutputStream 来实现的,整个序列化过程使用了大量的反射和临时变量,而且在序列化对象的时候,不仅会序列化当前对象本身,还需要递归序列化对象引用的其他对象。
- 整个过程计算非常复杂,而且因为存在大量反射和 GC 的影响,序列化的性能会比较差。另外一方面因为序列化文件需要包含的信息非常多,导致它的大小比 Class 文件本身还要大很多,这样又会导致 I/O 读写上的性能问题
- Serializable 使用 I/O 读写存储在硬盘上,序列化过程中产生大量的临时变量,会引起频繁 GC,效率低下。而 Parcelable 是直接在内存中读写,更加高效。
1 | |
serialVersionUID
它是用来辅助序列化和反序列化的,虽然在序列化的时候系统会自动生成一个 UID,但是还是推荐在手动提供一个 serialVersionUID。序列化操作的时候系统会把当前类的 serialVersionUID 写入序列化文件中,当反序列化的时候会去检测文件中的 serialVersionUID,判断它是否与当前类的 serialVersionUID 一致,如果一致就说明序列化类与当前类版本一致,可以反序列化成功,否则就可能抛异常。手动添加 serialVersionUID 的话,即使当类结构发生变化时,系统也会尽可能的恢复原有类结构,也不至于抛 InvalidClassException 异常。
父类的序列化
一个子类实现了 Serializable 接口,而父类没有实现 Serializable 接口,序列化该子类对象,然后反序列化后输出父类定义的成员变量的值,该数值与序列化时的数值不同。
要想将父类对象也序列化,就需要让父类对象也实现 Serializable 接口。如果父类对象不实现的话,就需要有默认的无参的构造方法。在父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造方法作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值,即初始值。
因此,我们也可以通过将不需要序列化的成员变量放到未 Serializable 的父类当中,达到和 transient 关键字一样的效果。
Parcelable
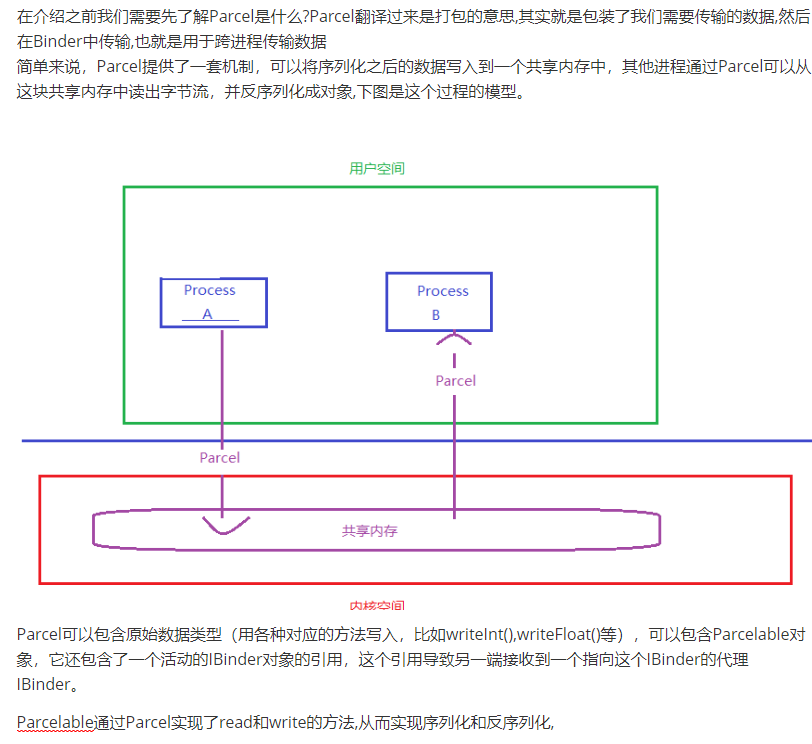
1 | |
Intent 序列化
为何 Intent 不能直接在组件间传递对象而要通过序列化机制?
- 因为跨进程
- Intent 在启动其他组件时,会离开当前应用程序进程,进入 ActivityManagerService 进程(intent. prepareToLeaveProcess ()),这也就意味着,Intent 所携带的数据要能够在不同进程间传输。首先我们知道,Android 是基于 Linux 系统,不同进程之间的 java 对象是无法传输,所以我们此处要对对象进行序列化,从而实现对象在应用程序进程和 ActivityManagerService 进程之间传输。
- 而 Parcel 或者 Serializable 都可以将对象序列化,其中,Serializable 使用方便,但性能不如 Parcel 容器,后者也是 Android 系统专门推出的用于进程间通信等的接口
Serial 的优点
- 相比起传统的反射序列化方案更加高效(没有使用反射)
- 性能相比传统方案提升了3倍 (序列化的速度提升了5倍,反序列化提升了2.5倍)
- 序列化生成的数据量(byte[])大约是之前的1/5
- 开发者对于序列化过程的控制较强,可定义哪些 object、field 需要被序列化
- 有很强的 debug 能力,可以调试序列化的过程(详见:调试)
数据的序列化
Serial 性能看起来还不错,但是对象的序列化要记录的信息还是比较多,在操作比较频繁的时候,对应用的影响还是不少的,这个时候我们可以选择使用数据的序列化。
json: 原生、gosn、fastjson(数据量大了的时候最快)