数据存储
SharedPreferences
基本使用
1 | |
SharedPreferences 本身是一个接口,程序无法直接创建 SharedPreferences 实例,只能通过 Context 提供的 getSharedPreferences(String name, int mode) 方法来获取 SharedPreferences 实例,name 表示要存储的 xml 文件名,第二个参数直接写 Context.MODE_PRIVAT,表示该 SharedPreferences 数据只能被本应用读写。当然还有 MODE_WORLD_READABLE 等,但是已经被废弃了,因为 SharedPreference 在多进程下表现并不稳定。
原理
保存基于 XML 文件存储的 key-value 键值对数据,在 /data/data/<\package name>/shared_prefs 目录下。
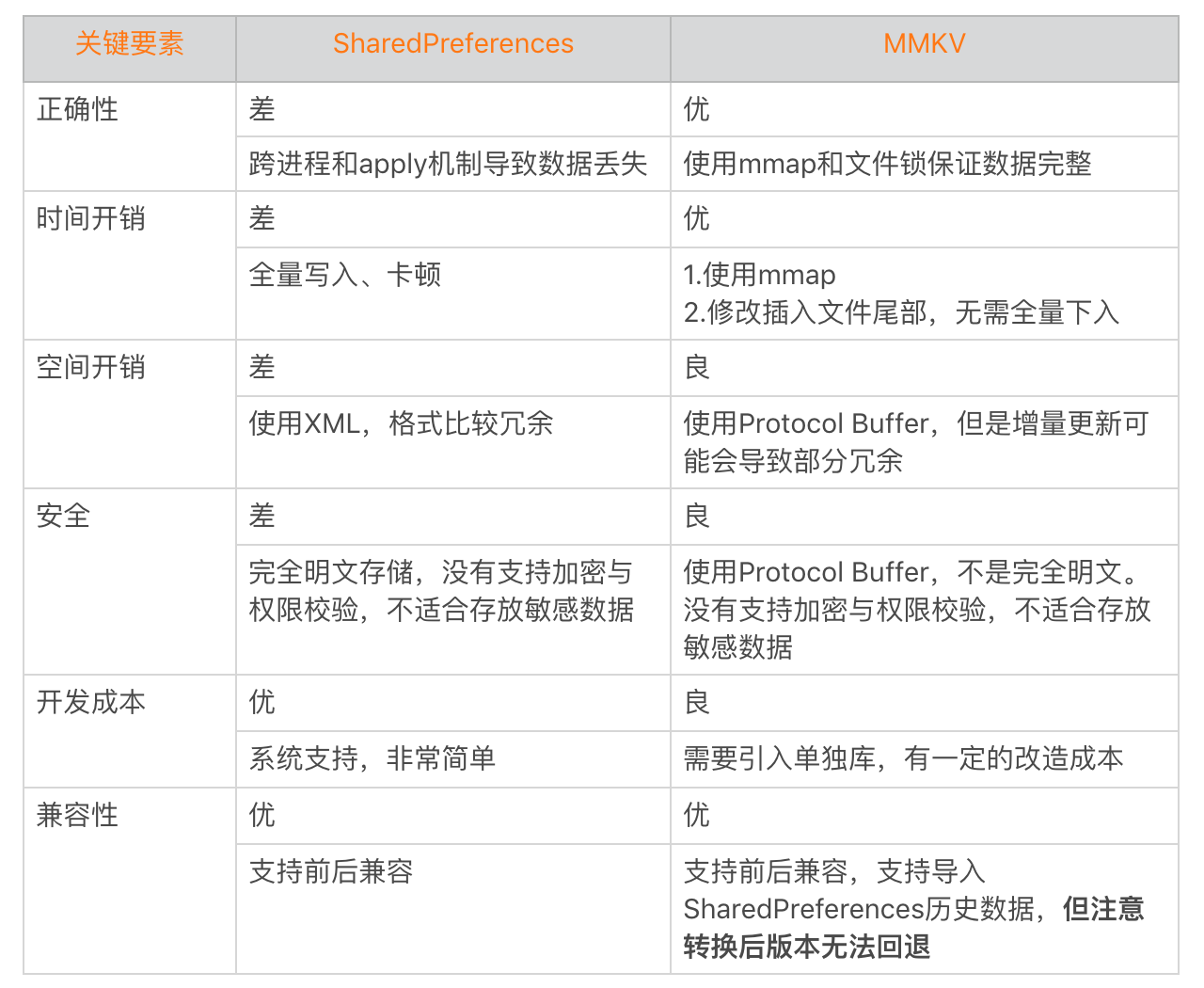
总结:
- sSharedPrefsCache 是一个 ArrayMap<String,ArrayMap<File,SharedPreferencesImpl>>,它会保存加载到内存中的 SharedPreferences 对象,ContextImpl 类中并没有定义将 SharedPreferences 对象移除 sSharedPrefsCache 的方法,所以一旦加载到内存中,就会存在直至进程销毁。相对的,也就是说,SP 对象一旦加载到内存,后面任何时间使用,都是从内存中获取,不会再出现读取磁盘的情况
- key 是包名
- 获取 SP 只能通过 ContextImpl#getSharedPerferences 来获取,它里面首先通过 mSharedPrefsPaths 根据传入的 name 拿到 File ,然后根据 File 从 ArrayMap<File, SharedPreferencesImpl> cache 里取出对应的 SharedPrederenceImpl 实例
- SharedPreferencesImpl 实例化的时候会启动子线程来读取磁盘文件,但是在此之前如果通过 SharedPreferencesImpl#getXxx 或者 SharedPreferences.Editor 会阻塞 UI 线程,因为在从 SP 文件中读取数据或者往 SP 文件中写入数据的时候必须等待 SP 文件加载完
- 在 EditorImpl 中 putXxx 的时候,是通过 HashMap 来存储数据,提交的时候分为 commit 和 apply
- SP 的读写操作是线程安全的,它对 mMap 的读写操作用的是同一把锁,考虑到 SP 对象的生命周期与进程一致,一旦加载到内存中就不会再去读取磁盘文件,所以只要保证内存中的状态是一致的,就可以保证读写的一致性
apply () 和 commit ()
- 提交的时候分为 commit 和 apply,它们都会把修改先提交到内存中,然后在写入磁盘中。只不过 apply 是异步写磁盘,而 commit 可能是同步写磁盘也可能是异步写磁盘,在于前面是否还有写磁盘任务
- 如果频繁操作的话 apply 的性能会优于 commit, apply 会将最后修改内容写入磁盘。
- 但是如果希望立刻获取存储操作的结果,并据此做相应的其他操作,应当使用 commit。
对于 apply 和 commit ,它是如何保证同步的呢?在这两个方法里都有 mcr.writtenToDiskLatch.await(),它其实是一个 CountDownLatch。
CountDownLatch 是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完成后在执行。
缺点
- 跨进程不安全。SharedPreferences 在跨进程频繁读写有可能导致数据全部丢失。根据线上统计,SP 大约会有万分之一的损坏率。
- 加载缓慢。SharedPreferences 文件的加载使用了异步线程,而且加载线程并没有设置线程优先级,如果这个时候主线程读取数据就需要等待文件加载线程的结束。
这就导致出现主线程等待低优先级线程锁的问题,比如一个 100KB 的 SP 文件读取等待时间大约需要 50~100ms,我建议提前用异步线程预加载启动过程用到的 SP 文件。 - 全量写入。无论是调用 commit () 还是 apply (),即使我们只改动其中的一个条目,都会把整个内容全部写到文件。而且即使我们多次写入同一个文件,SP 也没有将多次修改合并为一次,这也是性能差的重要原因之一。ANR
- 卡顿。由于提供了异步落盘的 apply 机制,在崩溃或者其他一些异常情况可能会导致数据丢失。所以当应用收到系统广播,或者被调用 onPause 等一些时机,系统会强制把所有的 SharedPreferences 对象数据落地到磁盘。如果没有落地完成,这时候主线程会被一直阻塞。
建议
- 强烈建议不要在 SP 里面存储特别大的 key/value ,有助于减少卡顿 / ANR
- 请不要高频的使用 apply,尽可能的批量提交;commit 直接在主线程操作,更要注意了
- 不要使用 MODE_MULTI_PROCESS
- 高频写操作的 key 与高频读操作的 key 可以适当的拆分文件,以减少同步锁竞争 (一次全部加载)
- 不要连续多次 edit,每次 edit 就是打开一次文件,应该获取一次 edit,然后多次执行 putXxx,减少内存波动,所以在封装方法的时候要注意了
MMKV
mmap 将一个文件或者其它对象映射进内存。(linux 上的东西)
常规文件操作需要从磁盘到页缓存再到用户主存的两次数据拷贝。(从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中)
而 mmap 操控文件,只需要从磁盘到用户主存的一次数据拷贝过程。说白了,mmap 的关键点是实现了用户空间和内核空间的数据直接交互而省去了空间不同数据不通的繁琐过程。因此 mmap 效率更高。
数据库
- 首先进行自定义一个类进行继承 SQLiteOpenHelper, 因为如果继承 SQLiteDatabase 那么会,要覆盖其中的许多的方法。如果已经有数据库,就不需要 sqliteopenhelper
MysqlLite (Context context, String name, CursorFactory factory, int version)传入当前的应用环境, 数据库的名称,游标的工厂, 版本号, 让底层为你进行创建数据库 - oncreate (SQLiteDatabase db): 当数据库创建好之后进行运行的函数,主要是在数据库创建好之后进行创建表
- onUpgrade (SQLiteDatabase db, int oldVersion, int newVersion): 当数据库进行更新后需要进行执行的方法
- integer 表示整型,real 表示浮点型,text 表示文本类型,blob 表示二进制类型。另外, primary key 将 id 列设为主键,并用 autoincrement 关键字表示 id 列是自增长的
1 | |
数据存储
http://peiniwan.github.io/2024/04/2c2842117e6b.html